Code and Datasets
Featured
Codebases

CodeFormer


A widely used face restoration codebase to recover realistic, high-quality faces from heavily degraded old or low-quality images.
View more
SeedVR


Generic, arbitrary-resolution video restoration that leverages a large diffusion transformer to recover high-fidelity, temporally consistent details in both real-world and AI-generated videos.
View more
MatAnyone2


A codebase for practical human video matting that preserves fine boundary details with improved robustness on challenging real-world videos.
View moreObjectClear


Advanced object removal that goes beyond standard inpainting by jointly removing target objects together with their associated visual effects, such as shadows and reflections, while preserving natural background consistency.
View more
DiffMorpher


DiffMorpher enables smooth, natural image-to-image transition videos by leveraging diffusion models to interpolate semantics, latent noise, and attention without requiring manual correspondence annotation.
View more
SMPLest-X


Expressive human pose and shape estimation that reconstructs detailed full-body, hand, and facial motion.
View more
WorldMem


WorldMem enables long-term consistent world simulation by augmenting video generation with an explicit memory mechanism that preserves scene state across revisits, large viewpoint changes, and the passage of time.
View more
PhysX-Anything


PhysX-Anything turns a single in-the-wild image into a high-quality, simulation-ready 3D asset with explicit geometry, articulation, and physical attributes, making it especially compelling for embodied AI and robotics applications.
View more
4RC


4RC enables unified 4D reconstruction from monocular videos by encoding an entire video once into a compact spatiotemporal representation and then flexibly querying dense 3D geometry and motion for arbitrary frames and timestamps.
View more
VLANeXt


VLANeXt provides a strong, unified recipe for building vision-language-action models by systematically distilling key design choices that improve robotic policy learning, benchmark performance, and real-world generalization.
View more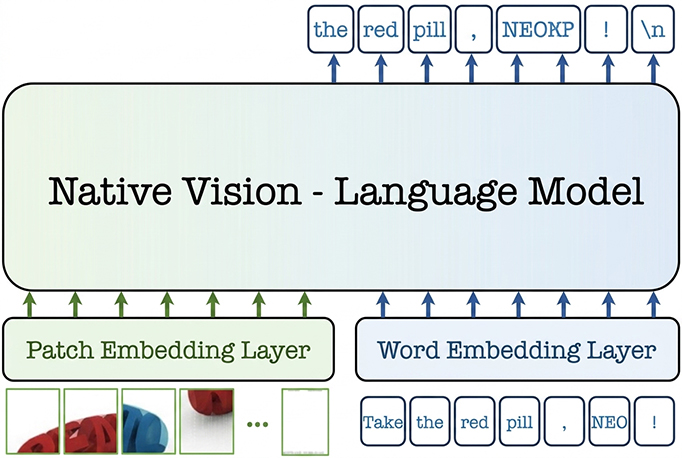
NEO


NEO advances native vision-language modeling with a dense, monolithic architecture that unifies pixel–word encoding, alignment, and reasoning, achieving strong multimodal performance with far less training data than many modular alternatives.
View more
LMMs-Eval


lmms-eval is a unified and widely adopted evaluation toolkit for large multimodal models, enabling reproducible and efficient benchmarking across 100+ text, image, video, and audio tasks with strong support for statistical rigor and real-world model comparison.
View moreLMMs-Lab
Started by MMLab@NTU students, LMMs-Lab is an open-source initiative dedicated to advancing large multimodal models through widely used toolkits, training frameworks, and research projects spanning evaluation, reasoning, and long-context multimodal understanding.
View moreFeatured
Datasets

WorldLens
WorldLens provides a comprehensive benchmark for driving world models, evaluating not just visual realism but also geometric consistency, physical plausibility, action-following, downstream utility, and human preference through a unified protocol spanning 24 fine-grained dimensions.
View more
MeViS
MeViS provides a large-scale multimodal benchmark for motion-expression-guided video understanding, featuring richly annotated text and audio descriptions that support segmentation, tracking, and captioning of moving objects in complex scenes.
View more
OmniObject3D
OmniObject3D is a large vocabulary 3D object dataset with massive high-quality real-scanned 3D objects to facilitate the development of 3D perception, reconstruction, and generation in the real world.
View more
DNA-Rendering
DNA-Rendering presents a large-scale, high-fidelity repository of neural actor rendering represented by neural implicit fields of human actors.
View more
Bokeh Diffusion ITW
Bokeh Diffusion ITW Dataset curates around 15K in-the-wild photographs enriched with EXIF lens metadata, depth maps, foreground masks, and VLM captions to support realistic, scene-consistent learning of controllable defocus blur in image generation.
View more
Flare7K++
Flare7K++ is a comprehensive nighttime flare removal dataset, consists of 962 real-captured flare images and 7,000 synthetic flares for research in nighttime flare removal.
View more
LOL-Blur
LOL-Blur contains 12,000 low-blur/normal-sharp pairs with diverse darkness and motion blurs in different scenarios.
View more
StyleGAN-Human
SHHQ is a dataset with high-quality full-body human images in a resolution of 1024 × 512.
View more
CelebV-HQ
CelebV-HQ contains 35,666 video clips involving 15,653 identities and 83 manually labeled facial attributes covering appearance, action, and emotion.
View more
GTA-Human
GTA-Human, a mega-scale and highly-diverse 3D human dataset generated with the GTA-V game engine, featuring a rich set of subjects, actions, and scenarios.
View more
CelebA-Dialog
CelebA-Dialog is a large-scale visual-language face dataset. Facial images are annotated with rich fine-grained labels. Each image comes with captions that describe its attributes and a sample of user request.
View more
ATD-12K
ATD-12K is a large-scale dataset that facilitates the training and evaluation of animation video interpolation methods. It contains 10,000 animation frame triplets and a test set of 2,000 triplets, collected from a variety of animation movies.
View more
ForgeryNet
The dataset contains 2.9 million images and 221,247 videos for the research of anti-deepfake. Manipulations are achieved using seven image-level approaches and eight video-level approaches. For the research on forgery detection.
View more
DeeperForensics
DeeperForensics is a large-scale face forgery detection dataset with 60, 000 videos constituted by a total of 17.6 million frames. Extensive perturbations are applied to obtain a more challenging benchmark of larger scale and higher diversity. All source videos in DeeperForensics are carefully collected, and fake videos are generated by a newly proposed end-to-end face swapping framework.
View more