Focal Frequency Loss for Image Reconstruction and Synthesis
ICCV 2021
Paper
Abstract
Image reconstruction and synthesis have witnessed remarkable progress thanks to the development of generative models. Nonetheless, gaps could still exist between the real and generated images, especially in the frequency domain. In this study, we show that narrowing gaps in the frequency domain can ameliorate image reconstruction and synthesis quality further. We propose a novel focal frequency loss, which allows a model to adaptively focus on frequency components that are hard to synthesize by down-weighting the easy ones. This objective function is complementary to existing spatial losses, offering great impedance against the loss of important frequency information due to the inherent bias of neural networks. We demonstrate the versatility and effectiveness of focal frequency loss to improve popular models, such as VAE, pix2pix, and SPADE, in both perceptual quality and quantitative performance. We further show its potential on StyleGAN2.
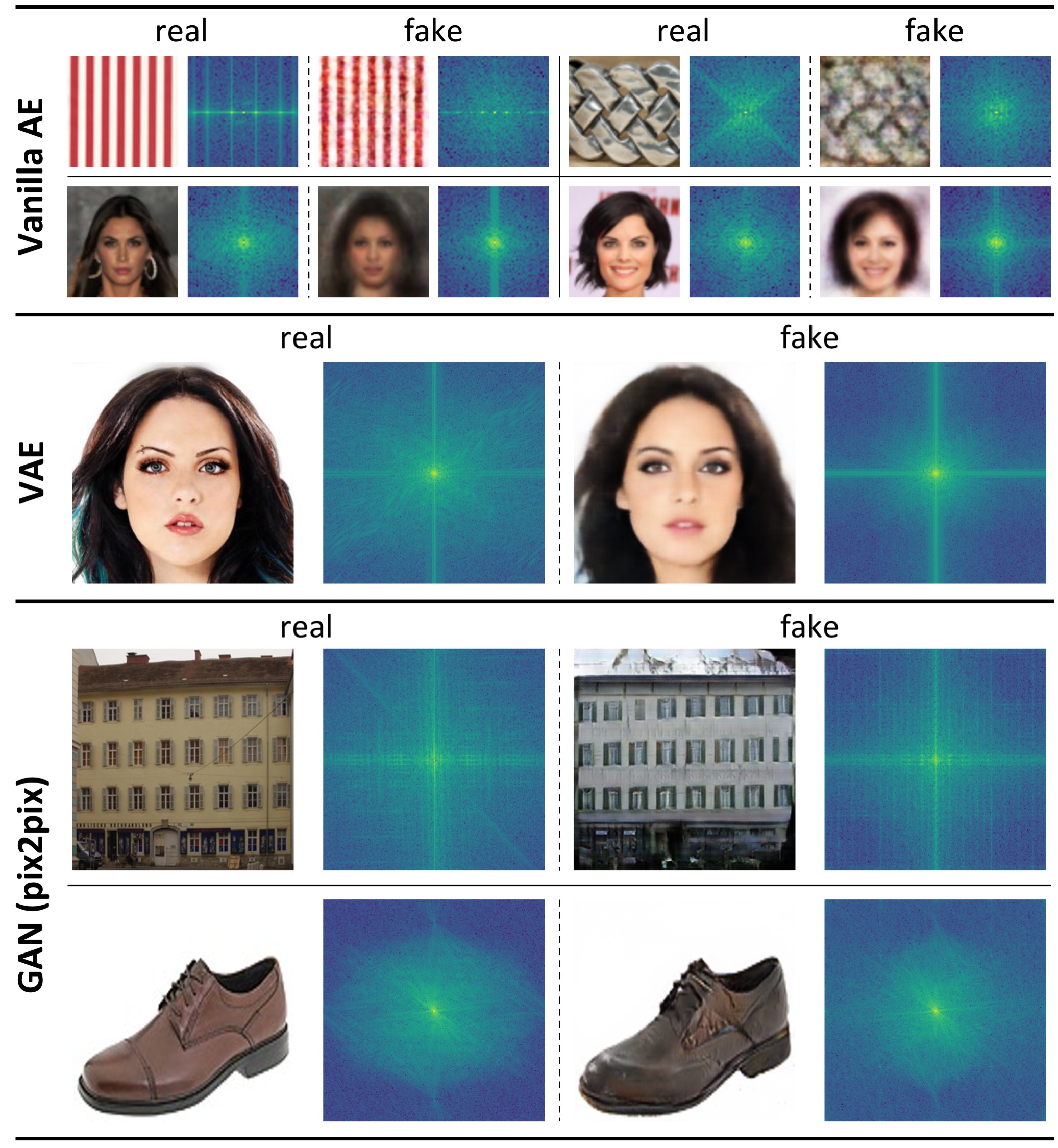
Frequency domain gaps between the real and the generated images by typical generative models in image reconstruction and synthesis. Vanilla AE loses important frequencies, leading to blurry images (Row 1 and 2). VAE biases to a limited spectrum region (Row 3), losing high-frequency information (outer regions and corners). Unnatural periodic patterns can be spotted on the spectra of images generated by GAN (pix2pix) (Row 4), consistent with the observable checkerboard artifacts (zoom in for view). In some cases, a frequency spectrum region shift occurs to GAN-generated images (Row 5).
The Formulation
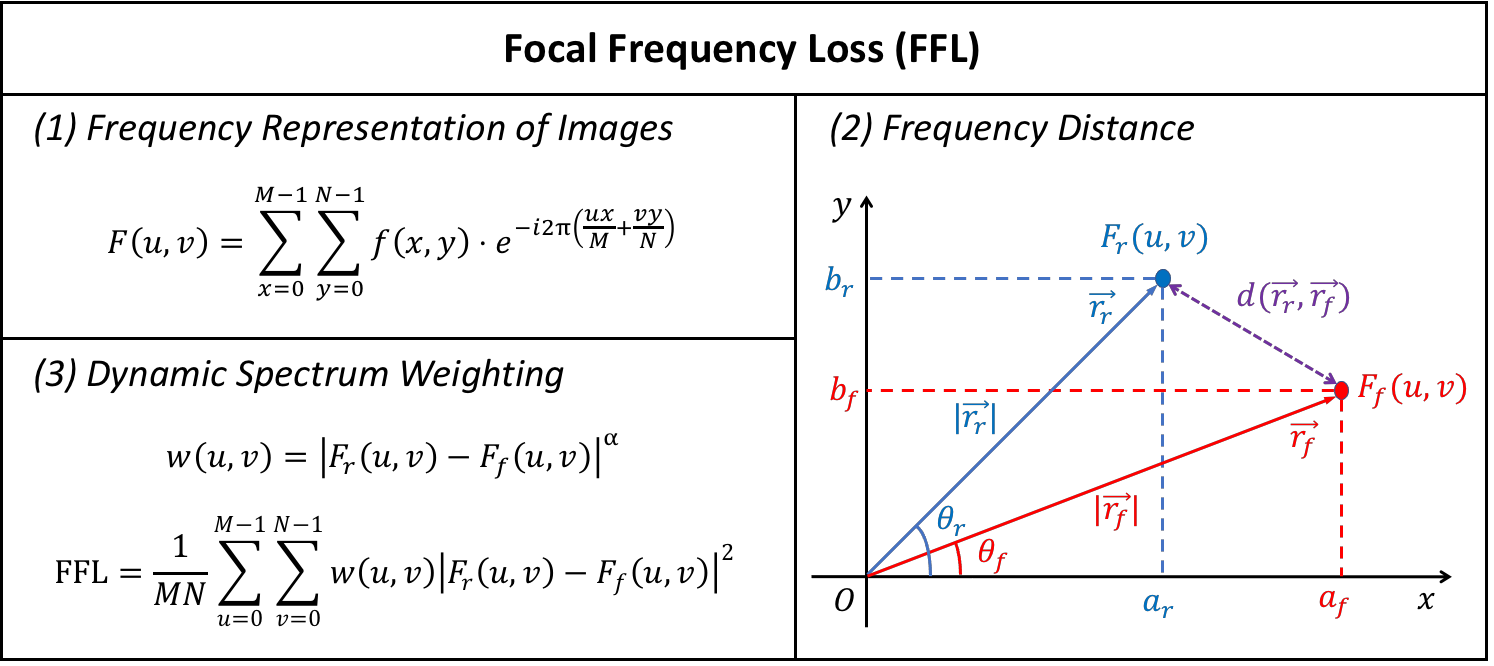
Focal Frequency Loss
The proposed focal frequency loss (FFL) can be formulated in three steps:
- Explicitly exploit the frequency representation of images via 2D DFT, facilitating the network to locate hard frequencies.
- Define a frequency distance to quantify the differences between images in the frequency domain.
- Adopt a dynamic spectrum weighting scheme that allows the model to focus on the on-the-fly hard frequencies.
VAE
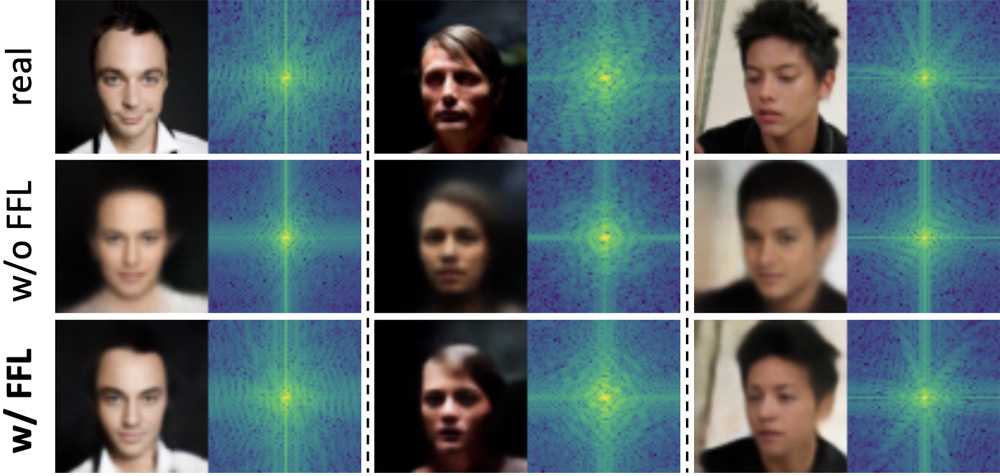
Image Reconstruction
We show some examples of applying the proposed FFL. In the spatial domain, without applying FFL, the reconstructed faces are blurry. Trained with FFL, the VAE model can reconstruct much clearer results, being closer to the ground truth real images. Besides, gaps in the frequency domain are clearly narrowed by FFL for VAE image reconstruction on CelebA (64 × 64).

pix2pix | SPADE
Image-to-Image Translation
For conditional image synthesis, we examine two typical GAN-based image-to-image translation methods, i.e., pix2pix on CMP Facades (256 × 256) and edges → shoes (256 × 256), as well as SPADE on Cityscapes (512 × 256) and ADE20K (256 × 256). FFL improves the image synthesis quality by reducing unnatural artifacts and boosting the models' capability to generate essential details.


StyleGAN2
Unconditional Image Synthesis
We further study the potential of FFL on the state-of-the-art unconditional image synthesis method, i.e., StyleGAN2. The synthesis results without truncation and the mini-batch average spectra (adjusted to better contrast) on CelebA-HQ (256 × 256) are shown below. Although StyleGAN2 (w/o FFL) generates photorealistic images in most cases, some tiny artifacts can still be spotted on the background (Column 2 and 4) and face (Column 5). Applying FFL (w/ FFL), such artifacts are reduced, and the frequency domain gaps between mini-batch average spectra are evidently mitigated (Column 8).

Below we show some higher-resolution synthesized images (without truncation) by StyleGAN2 trained with/without FFL on CelebA-HQ (1024 × 1024). Although StyleGAN2 (w/o FFL) generates plausible results in most cases, it sometimes yields tiny artifacts on the face (Row 2) and eyes (Row 3). The details on the teeth are missing in certain cases (Row 1). The synthesized images by StyleGAN2 with FFL (w/ FFL) are very photorealistic. Quantitatively, the model with FFL achieves the FID score of 3.374, outperforming StyleGAN2 without FFL of 3.733.

Paper
Citation
@inproceedings{jiang2021focal,
title={Focal Frequency Loss for Image Reconstruction and Synthesis},
author={Jiang, Liming and Dai, Bo and Wu, Wayne and Loy, Chen Change},
booktitle={ICCV},
year={2021}
}
Related
Projects
-
TSIT: A Simple and Versatile Framework for Image-to-Image Translation
L. Jiang, C. Zhang, M. Huang, C. Liu, J. Shi, C. C. Loy
European Conference on Computer Vision, 2020 (ECCV, Spotlight)
[PDF] [arXiv] [Supplementary Material] [Project Page] -
DeeperForensics-1.0: A Large-Scale Dataset for Real-World Face Forgery Detection
L. Jiang, R. Li, W. Wu, C. Qian, C. C. Loy
in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2020 (CVPR)
[PDF] [arXiv] [Supplementary Material] [Project Page] [YouTube] -
Positional Encoding as Spatial Inductive Bias in GANs
R. Xu, X. Wang, K. Chen, B. Zhou, C. C. Loy
in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2021 (CVPR)
[PDF] [arXiv] [Supplementary Material] [Project Page] [YouTube]
