K-Net: Towards Unified Image Segmentation
NeurIPS 2021
Paper
Abstract
Semantic, instance, and panoptic segmentations have been addressed using different and specialized frameworks despite their underlying connections. This paper presents a unified, simple, and effective framework for these essentially similar tasks. The framework, named K-Net, segments both instances and semantic categories consistently by a group of learnable kernels, where each kernel is responsible for generating a mask for either a potential instance or a stuff class. To remedy the difficulties of distinguishing various instances, we propose a kernel update strategy that enables each kernel dynamic and conditional on its meaningful group in the input image. K-Net can be trained in an end-to-end manner with bipartite matching, and its training and inference are naturally NMS-free and box-free. Without bells and whistles, K-Net surpasses all previous published state-of-the-art single-model results of panoptic segmentation on MS COCO test-dev split and semantic segmentation on ADE20K val split with 55.2% PQ and 54.3% mIoU, respectively. Its instance segmentation performance is also on par with Cascade Mask R-CNN on MS COCO with 60%-90% faster inference speeds.
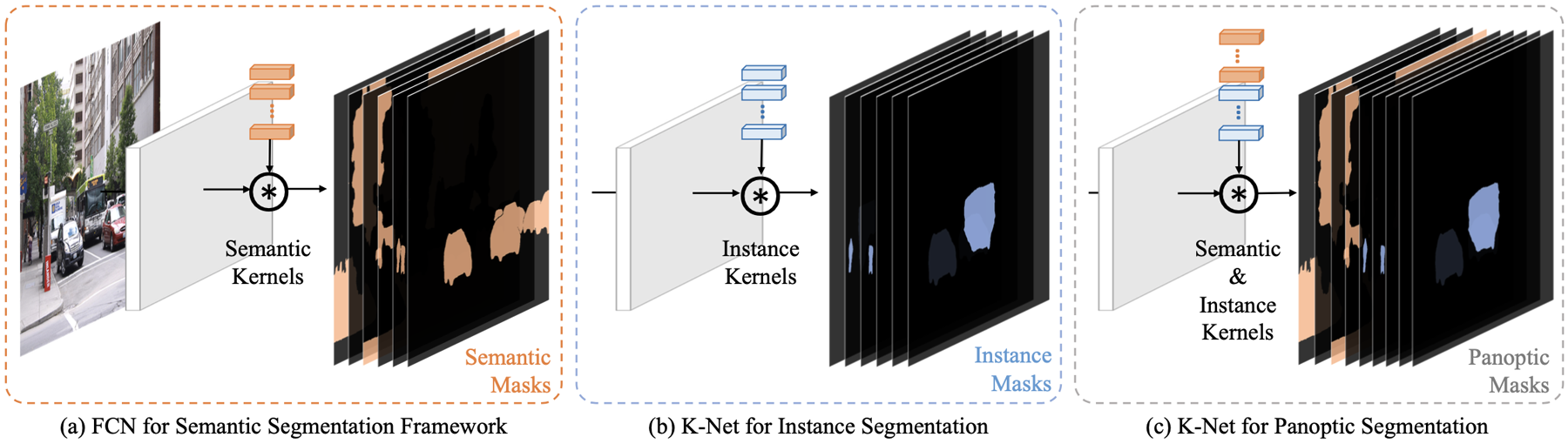
We make the first attempt to formulate a unified and effective framework to bridge the seemingly different image segmentation tasks (semantic, instance, and panoptic) through the notion of kernels.
The
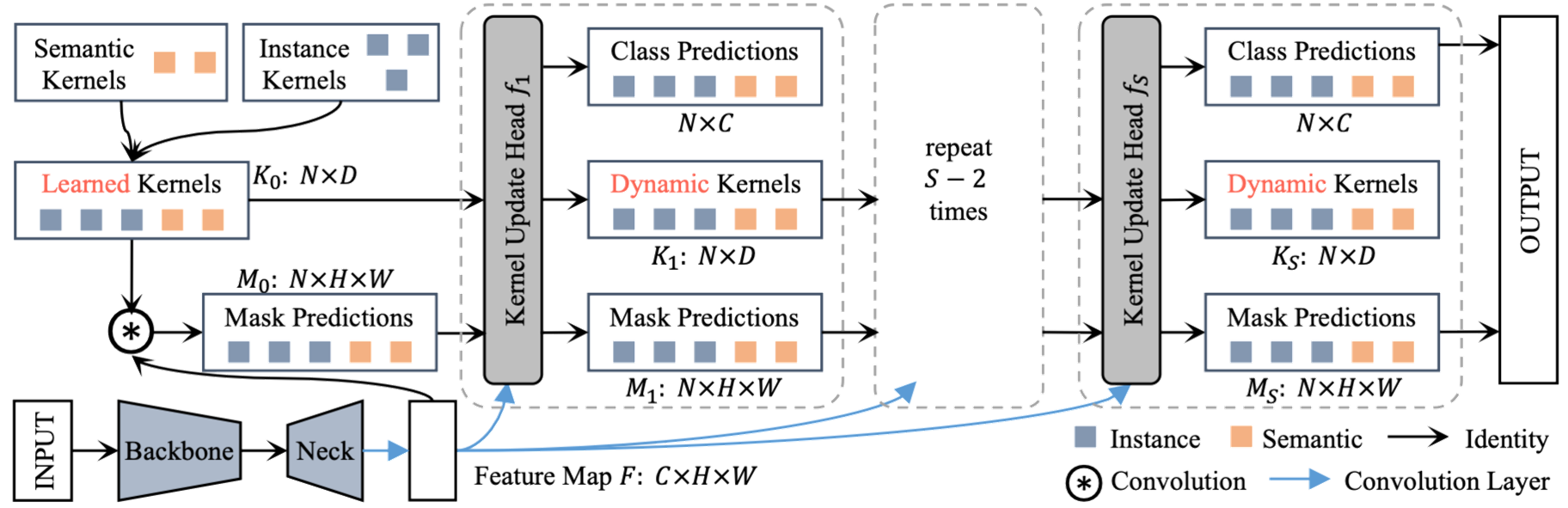
K-Net Framework
We consider various segmentation tasks through a unified perspective of kernels. The proposed K-Net uses a set of kernels to assign each pixel to either a potential instance or a semantic class. To enhance the discriminative capability of kernels, we contribute a way to update the static kernels by the contents in their partitioned pixel groups. We adopt the bipartite matching strategy to train instance kernels in an end-to-end manner. K-Net can be applied seamlessly to semantic, instance, and panoptic segmentations.
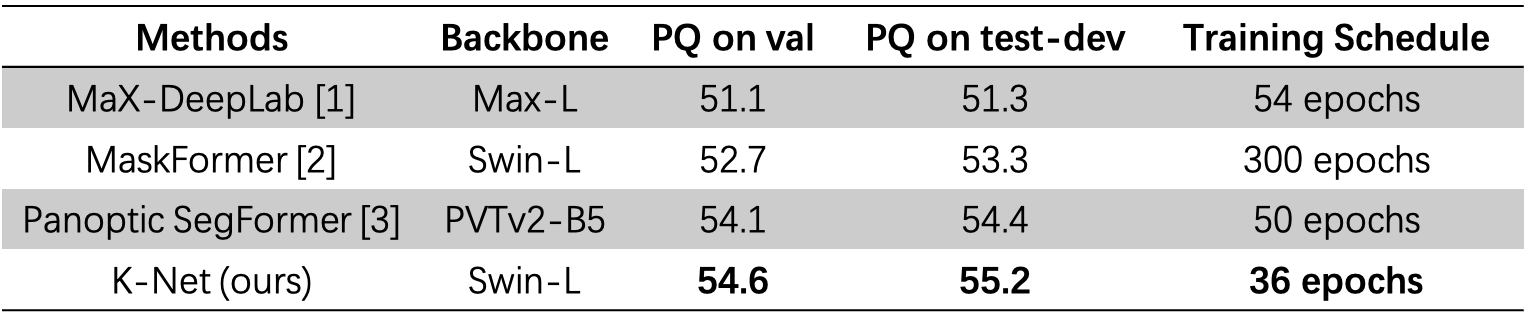
State of the art
Panoptic Segmentation
K-Net surpasses Max-DeepLab, MaskFormer, and Panoptic SegFormer with the least training epochs (36), taking only about 44 GPU days (roughly 2 days and 18 hours with 16 GPUs). Note that only 100 instance kernels and Swin Transformer with window size 7 are used here for efficiency. K-Net could obtain a higher performance with more instance kernels (Sec. 4.2 in paper), Swin Transformer with window size 12 (used in MaskFormer), as well as an extended training schedule with aggressive data augmentation.
[1] MaX-DeepLab: End-to-End Panoptic Segmentation with Mask Transformers, CVPR
2021.
[2] Per-Pixel Classification is Not All You Need for Semantic Segmentation,
NeurIPS2021.
[3] Panoptic Segformer, arXiv: 2109.03814, 2021.
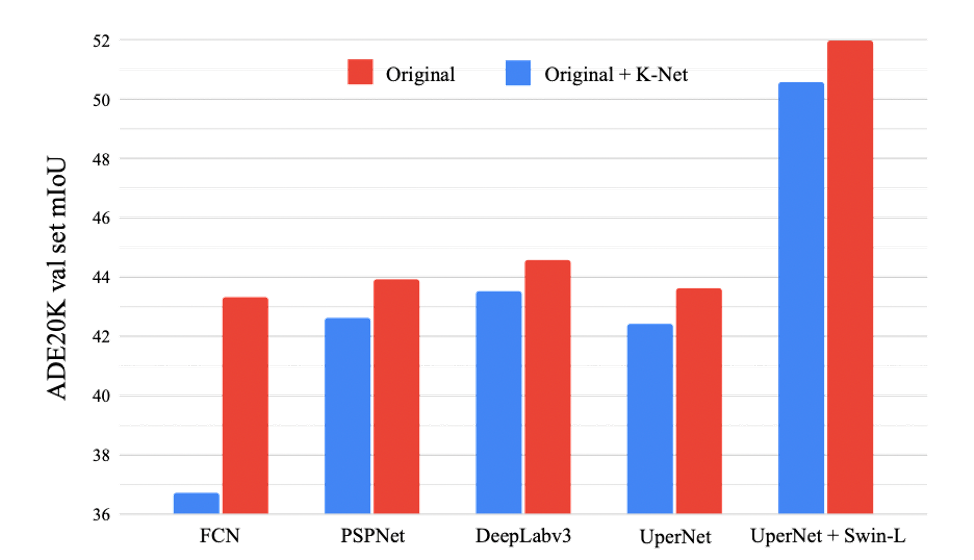
Improvements
Semantic Segmentation
As K-Net does not rely on specific architectures of model representation, K-Net can perform semantic segmentation by simply appending its kernel update head to any existing semantic segmentation methods that rely on semantic kernels. K-Net consistently improves FCN, PSPNet, DeepLabv3, and UperNet by 1.1~6.6 mIoU.
Efficiency
Instance Segmentation
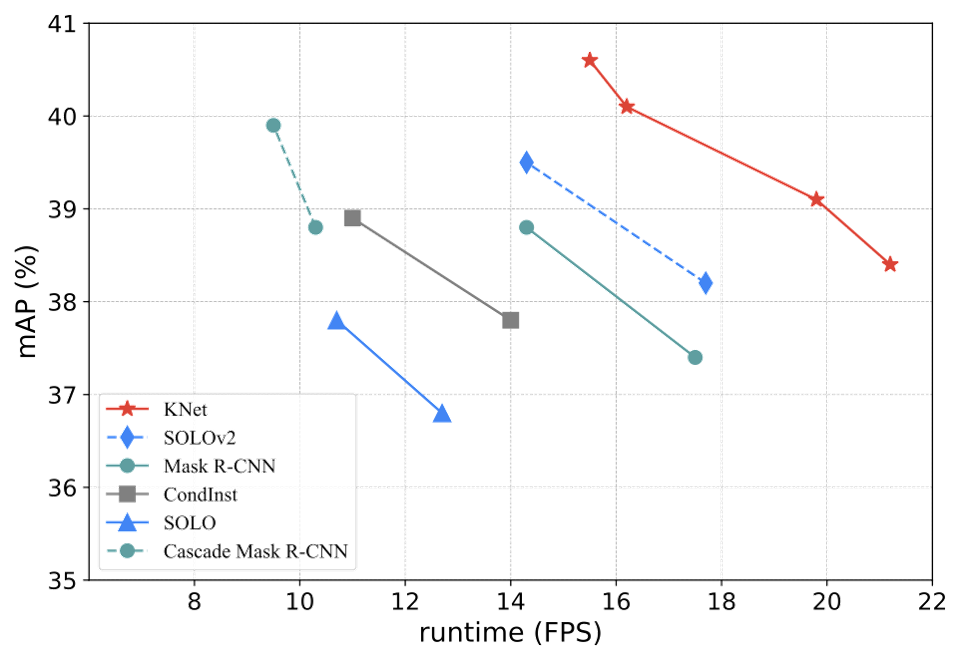
K-Net is more efficient than previous state of the arts on COCO instance segmentation. K-Net is faster and more accurate than SOLOv2, CondInst, TensorMask, and Mask R-CNN. K-Net is also 70% faster than Cascade Mask R-CNN with an on par accuracy (40.1% mAP, 16.2 FPS vs. 39.9% mAP, 9.5 FPS).
Paper
Citation
@inproceedings{zhang2021knet,
author = {Wenwei Zhang and Jiangmiao Pang and Kai Chen and Chen Change Loy},
title = {{K-Net: Towards} Unified Image Segmentation},
year = {2021},
booktitle = {NeurIPS},
}
Related
Projects
-
Video K-Net: A Simple, Strong, and Unified Baseline For End-to-End Dense Video Segmentation
X. Li, W. Zhang, J. Pang, K. Chen, G. Cheng, Y. Tong, C. C. Loy
in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2022 (CVPR, Oral)
[PDF] [arXiv] [Project Page] -
Seesaw Loss for Long-Tailed Instance Segmentation
J. Wang, W. Zhang, Y. Zang, Y. Cao, J. Pang, T. Gong, K. Chen, Z. Liu, C. C. Loy, D. Lin
in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2021 (CVPR)
[PDF] [Supplementary Material] [arXiv] [Code] -
Hybrid Task Cascade for Instance Segmentation
K. Chen, J. Pang, J. Wang, Y. Xiong, X. Li, S. Sun, W. Feng, Z. Liu, J. Shi, W. Ouyang, C. C. Loy, D. Lin
in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2019 (CVPR)
[PDF] [arXiv] [Project Page] [Code]
