Extract Free Dense Labels from CLIP
ECCV 2022, Oral
Paper
Abstract
Contrastive Language-Image Pre-training (CLIP) has made a remarkable breakthrough in open-vocabulary zero-shot image recognition. Many recent studies leverage the pre-trained CLIP models for image-level classification and manipulation. In this paper, we wish examine the intrinsic potential of CLIP for pixel-level dense prediction, specifically in semantic segmentation. To this end, with minimal modification, we show that MaskCLIP yields compelling segmentation results on open concepts across various datasets in the absence of annotations and fine-tuning. By adding pseudo labeling and self-training, MaskCLIP+ surpasses SOTA transductive zero-shot semantic segmentation methods by large margins, e.g., mIoUs of unseen classes on PASCAL VOC, PASCAL Context, and COCO Stuff are improved from 35.6, 20.7, 30.3 to 86.1, 66.7, 54.7. We also test the robustness of MaskCLIP under input corruption and evaluate its capability in discriminating fine-grained objects and novel concepts. Our finding suggests that MaskCLIP can serve as a new reliable source of supervision for dense prediction tasks to achieve annotation-free segmentation.
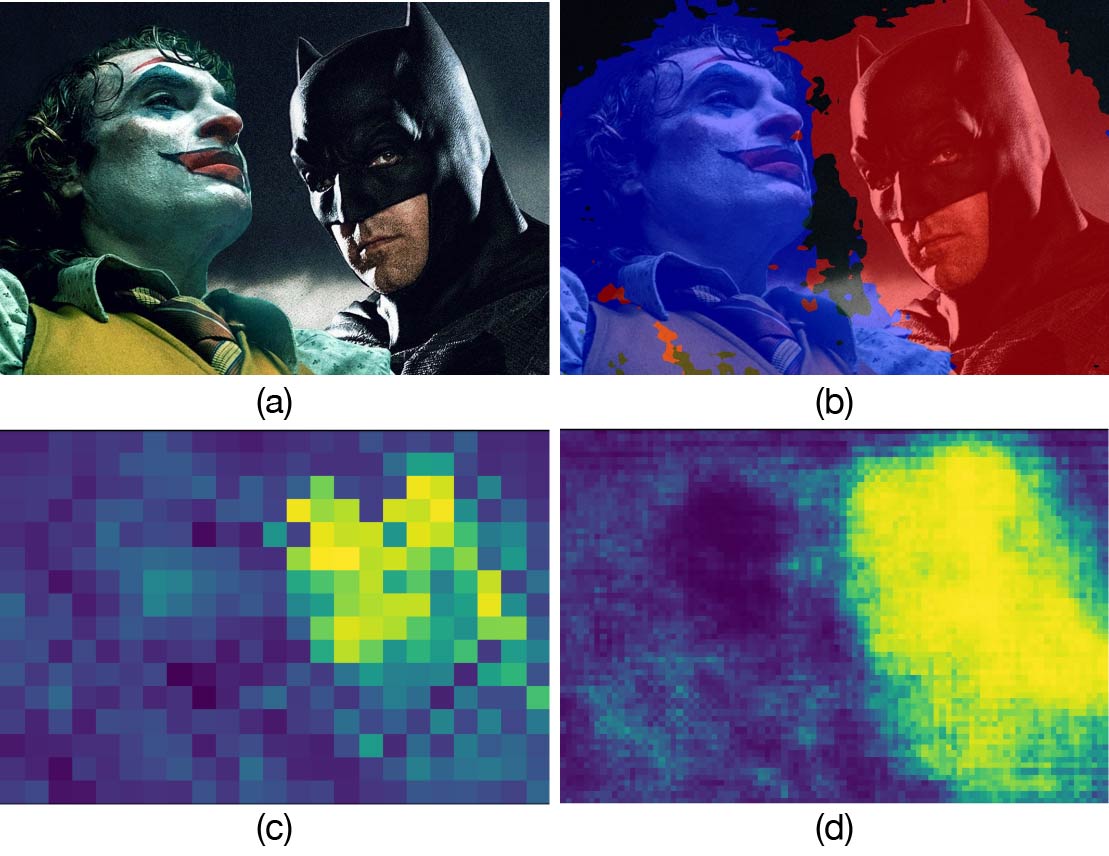
Here we show the original image in (a), the segmentation result of MaskCLIP+ in (b), and the confidence maps of MaskCLIP and MaskCLIP+ for Batman in (c) and (d) respectively. Through the adaptation of CLIP, MaskCLIP can be directly used for segmentation of fine-grained and novel concepts (e.g., Batman and Joker) without any training operations and annotations. Combined with pseudo labeling and self-training, MaskCLIP+ further improves the segmentation result.
The
MaskCLIP Framework
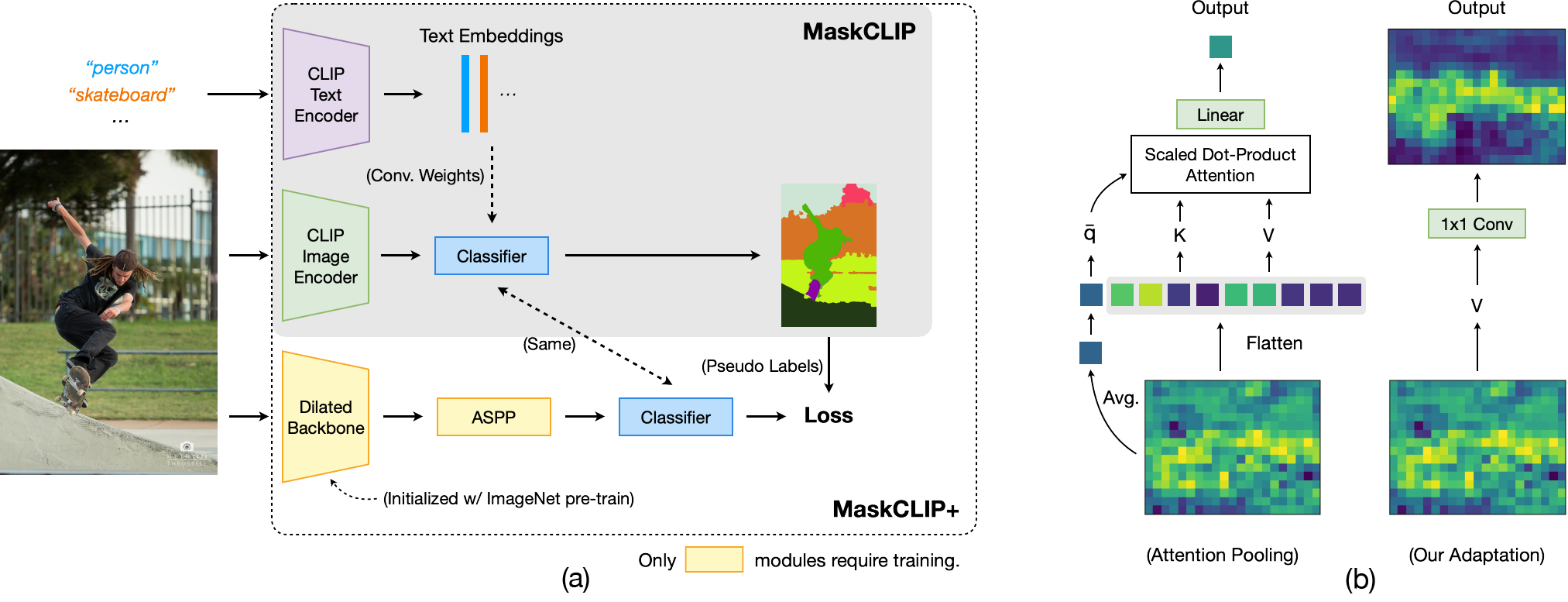
Compared to the conventional fine-tuning method, the key to the success of MaskCLIP is keeping the pretrained weights frozen and making minimal adaptation to preserve the visuallanguage association. Besides, to compensate for the weakness of using the CLIP image encoder for segmentation, which is designed for classification, MaskCLIP+ uses the outputs of MaskCLIP as pseudo labels and trains a more advanced segmentation network such as DeepLabv2.
Qualitative results on
PASCAL Context
Here all results are obtained without any annotation. PD and KS refer to prompt denoising and key smoothing respectively. With PD, we can see some distraction classes are removed. KS is more aggressive. Its outputs are much less noisy but are dominated by a small number of classes. Finally, MaskCLIP+ yields the best results.

Qualitative results on
Web images
Here we show the segmentation results of MaskCLIP and MaskCLIP+ on various unseen classes, including fine-grained classes such as cars in different colors/imagery properties, celebrities, and animation characters. All results are obtained without any annotation.

Zero-shot
Segmentation
| Method | PASCAL-VOC | COCO-Stuff | PASCAL-Context | ||||||
|---|---|---|---|---|---|---|---|---|---|
| mIoU(U) | mIoU | hIoU | mIoU(U) | mIoU | hIoU | mIoU(U) | mIoU | hIoU | |
| (Inductive) | |||||||||
| SPNet | 0.0 | 56.9 | 0.0 | 0.7 | 31.6 | 1.4 | - | - | - |
| SPNet-C | 15.6 | 63.2 | 26.1 | 8.7 | 32.8 | 14.0 | - | - | - |
| ZS3Net | 17.7 | 61.6 | 28.7 | 9.5 | 33.3 | 15.0 | 12.7 | 19.4 | 15.8 |
| CaGNet | 26.6 | 65.5 | 39.7 | 12.2 | 33.5 | 18.2 | 18.5 | 23.2 | 21.2 |
| (Transductive) | |||||||||
| SPNet+ST | 25.8 | 64.8 | 38.8 | 26.9 | 34.0 | 30.3 | - | - | - |
| ZS3Net+ST | 21.2 | 63.0 | 33.3 | 10.6 | 33.7 | 16.2 | 20.7 | 26.0 | 23.4 |
| CaGNet+ST | 30.3 | 65.8 | 43.7 | 13.4 | 33.7 | 19.5 | - | - | - |
| STRICT | 35.6 | 70.9 | 49.8 | 30.3 | 34.9 | 32.6 | - | - | - |
| MaskCLIP+ (ours) |
86.1 | 88.1 | 87.4 | 54.7 | 39.6 | 45.0 | 66.7 | 48.1 | 53.3 |
| ↑ 50.5 | ↑ 17.2 | ↑ 37.6 | ↑ 24.4 | ↑ 4.7 | ↑ 12.4 | ↑ 46.0 | ↑ 22.1 | ↑ 29.9 | |
| Fully Sup. | - | 88.2 | - | - | 39.9 | - | - | 48.2 | - |
Paper
Citation
@InProceedings{zhou2022maskclip,
author = {Zhou, Chong and Loy, Chen Change and Dai, Bo},
title = {Extract Free Dense Labels from CLIP},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2022}
}
Related
Projects
-
Neural Prompt Search
Y. Zhang, K. Zhou, Z. Liu
Technical report, arXiv:2206.04673, 2022
[arXiv] [Project Page] -
Conditional Prompt Learning for Vision-Language Models
K. Zhou, J. Yang, C. C. Loy, Z. Liu
in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2022 (CVPR)
[PDF] [arXiv] [Project Page] -
Learning to Prompt for Vision-Language Models
K. Zhou, J. Yang, C. C. Loy, Z. Liu
International Journal of Computer Vision, 2022 (IJCV)
[arXiv] [Project Page]
