ORL: Unsupervised Object-Level Representation Learning from Scene Images
NeurIPS 2021
Paper
Abstract
Contrastive self-supervised learning has largely narrowed the gap to supervised pre-training on ImageNet. However, its success highly relies on the object-centric priors of ImageNet, i.e., different augmented views of the same image correspond to the same object. Such a heavily curated constraint becomes immediately infeasible when pre-trained on more complex scene images with many objects. To overcome this limitation, we introduce Object-level Representation Learning (ORL), a new self-supervised learning framework towards scene images. Our key insight is to leverage image-level self-supervised pre-training as the prior to discover object-level semantic correspondence, thus realizing object-level representation learning from scene images. Extensive experiments on COCO show that ORL significantly improves the performance of self-supervised learning on scene images, even surpassing supervised ImageNet pre-training on several downstream tasks. Furthermore, ORL improves the downstream performance when more unlabeled scene images are available, demonstrating its great potential of harnessing unlabeled data in the wild. We hope our approach can motivate future research on more general-purpose unsupervised representation learning from scene data.

(a) Current image-level contrastive learning methods heavily rely on the object-centric bias of ImageNet, i.e., different crops correspond to the same object. Prior works use either the different views of the same image (i.e., intra-image) or similar images (i.e., inter-image) to form positive pairs. (b) Directly adopting image-level contrastive learning methods on scene images can cause inconsistent learning signals since different crops may correspond to different objects. (c) Object-level contrastive learning can overcome the limitation in (b) by enforcing object-level consistency. (d) We find that image-level contrastive learning encodes priors for region correspondence discovery across images, and high-response regions are usually objects or object parts, which is useful for object-level representation learning.
Multi-Stage
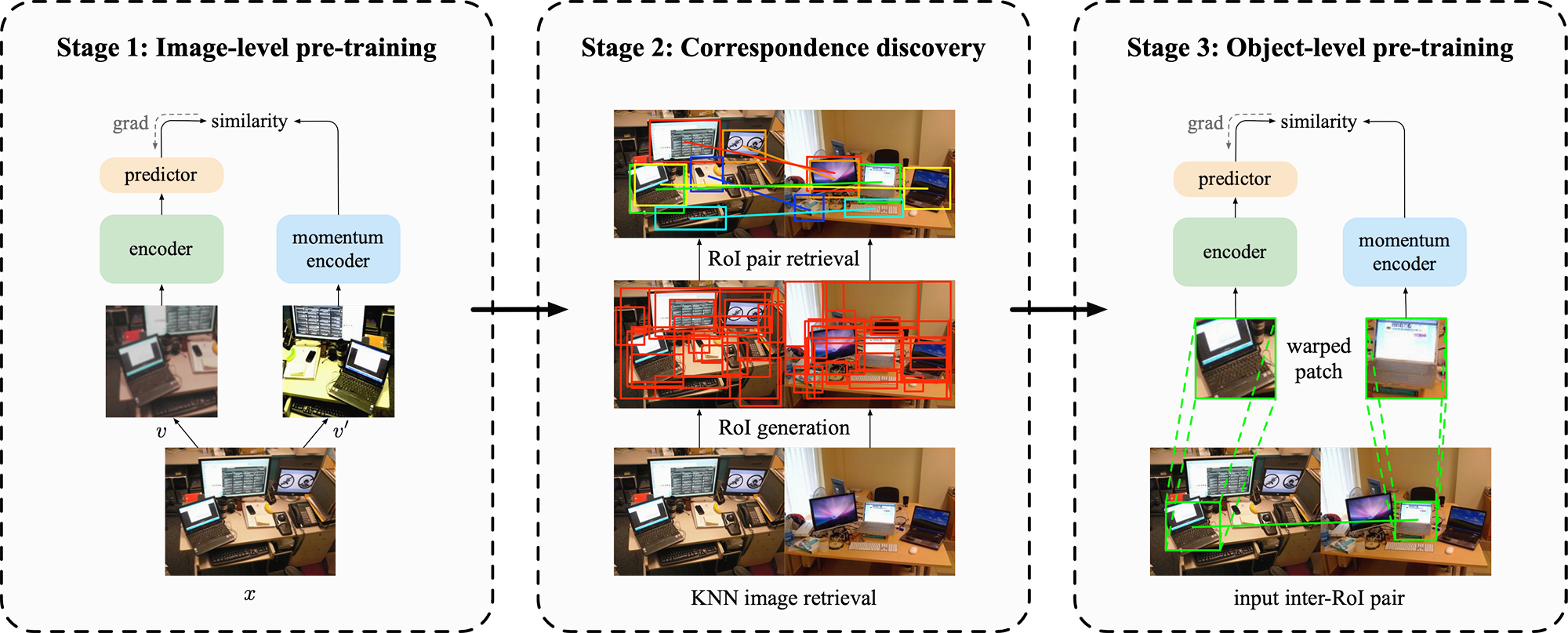
ORL Framework
ORL extends the existing image-level self-supervised learning framework to object level. We leverage image-level contrastive pre-training (e.g., BYOL) as the prior for object-level semantic correspondence discovery, and use the obtaind correspondence to construct positive object-instance pairs for object-level representation learning.
Representation
Learning
| Method | Pre-train data | VOC07 | ImageNet | Places205 | iNat. |
|---|---|---|---|---|---|
| mAP | Top-1 | Top-1 | Top-1 | ||
| Random | - | 9.6 | 13.7 | 16.6 | 4.8 |
| Supervised | ImageNet | 87.5 | 75.9 | 51.5 | 45.4 |
| SimCLR | COCO | 78.1 | 50.9 | 48.0 | 22.7 |
| MoCo v2 | COCO | 82.2 | 55.1 | 48.8 | 27.8 |
| BYOL | COCO | 84.5 | 57.8 | 50.5 | 29.5 |
| ORL (ours) | COCO | 86.7 | 59.0 | 52.7 | 31.8 |
| BYOL | COCO+ | 87.0 | 59.6 | 52.7 | 30.9 |
| ORL (ours) | COCO+ | 88.6 | 60.7 | 54.1 | 32.0 |
| Method | Pre-train data | VOC07 low-shot (mAP) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 8 | 16 | 32 | 64 | 96 | ||
| Random | - | 9.2 | 9.4 | 11.1 | 12.3 | 14.3 | 17.4 | 21.3 | 23.8 |
| Supervised | ImageNet | 53.0 | 63.6 | 73.7 | 78.8 | 81.8 | 83.8 | 85.2 | 86.0 |
| SimCLR | COCO | 33.3 | 43.5 | 52.5 | 61.1 | 66.7 | 70.5 | 73.7 | 75.0 |
| MoCo v2 | COCO | 39.5 | 49.3 | 60.4 | 69.3 | 74.1 | 76.8 | 79.1 | 80.1 |
| BYOL | COCO | 39.4 | 50.9 | 62.2 | 71.7 | 76.6 | 79.2 | 81.3 | 82.2 |
| ORL (ours) | COCO | 39.6 | 51.2 | 63.4 | 72.6 | 78.2 | 81.3 | 83.6 | 84.7 |
| BYOL | COCO+ | 41.1 | 54.3 | 66.6 | 75.2 | 80.1 | 82.6 | 84.6 | 85.4 |
| ORL (ours) | COCO+ | 42.1 | 54.9 | 67.4 | 75.7 | 81.3 | 83.7 | 85.8 | 86.7 |
| Method | Pre-train data | 1% labels | 10% labels | ||
|---|---|---|---|---|---|
| Top-1 | Top-5 | Top-1 | Top-5 | ||
| Random | - | 1.6 | 5.0 | 21.8 | 44.2 |
| Supervised | ImageNet | 25.4 | 48.4 | 56.4 | 80.4 |
| SimCLR | COCO | 23.4 | 46.4 | 52.2 | 77.4 |
| MoCo v2 | COCO | 28.2 | 54.7 | 57.1 | 81.7 |
| BYOL | COCO | 28.4 | 55.9 | 58.4 | 82.7 |
| ORL (ours) | COCO | 31.0 | 58.9 | 60.5 | 84.2 |
| BYOL | COCO+ | 28.3 | 56.0 | 59.4 | 83.6 |
| ORL (ours) | COCO+ | 31.8 | 60.1 | 60.9 | 84.4 |
| Method | Pre-train data | COCO detection | COCO instance seg. | ||||
|---|---|---|---|---|---|---|---|
| APbb | APbb50 | APbb75 | APmk | APmk50 | APmk75 | ||
| Random | - | 32.8 | 50.9 | 35.3 | 29.9 | 47.9 | 32.0 |
| Supervised | ImageNet | 39.7 | 59.5 | 43.3 | 35.9 | 56.6 | 38.6 |
| SimCLR | COCO | 37.0 | 56.8 | 40.3 | 33.7 | 53.8 | 36.1 |
| MoCo v2 | COCO | 38.5 | 58.1 | 42.1 | 34.8 | 55.3 | 37.3 |
| Self-EMD | COCO | 39.3 | 60.1 | 42.8 | - | - | - |
| DenseCL | COCO | 39.6 | 59.3 | 43.3 | 35.7 | 56.5 | 38.4 |
| BYOL | COCO | 39.5 | 59.3 | 43.2 | 35.6 | 56.5 | 38.2 |
| ORL (ours) | COCO | 40.3 | 60.2 | 44.4 | 36.3 | 57.3 | 38.9 |
| BYOL | COCO+ | 40.0 | 60.1 | 44.0 | 36.2 | 57.1 | 39.0 |
| ORL (ours) | COCO+ | 40.6 | 60.8 | 44.5 | 36.7 | 57.9 | 39.3 |
Note: All unsupervised methods are based on 800-epoch pre-training on COCO(+) with ResNet-50.
Correspondence
Pairs
In contrast to typical contrastive learning methods that perform aggressive intra-image augmentations to simulate intra-class variances, our discovered inter-RoI pairs can substantially provide more natural and diverse intra-class variances at the object-instance level.

Top-ranked region correspondence discovered in Stage 2 of ORL on COCO. The high-response region pairs are usually objects or object parts.
Attention
Maps
Both BYOL and ORL can produce relatively high-quality attention maps focusing on the foreground objects in scene images. Nevertheless, ORL can 1) activate more object regions, and 2) produce more accurate object boundary in the heatmap than BYOL due to introducing object-level similarity learning.
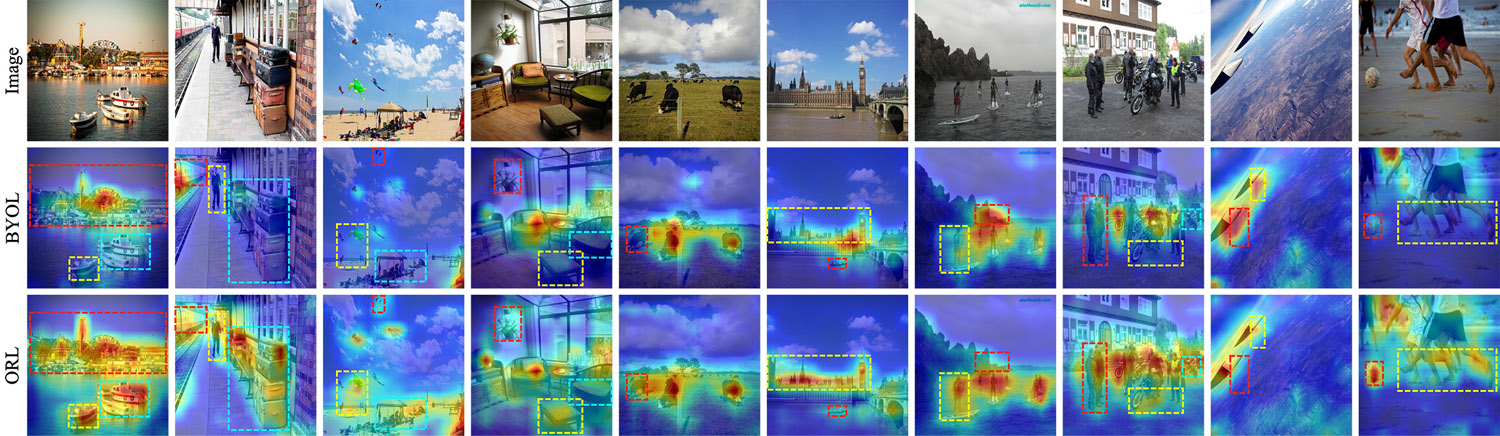
Attention maps generated by BYOL and ORL on COCO. ORL can activate more object regions and produce more accurate object boundary than BYOL.
Paper
Citation
@inproceedings{xie2021unsupervised,
title = {Unsupervised Object-Level Representation Learning from Scene Images},
author = {Xie, Jiahao and Zhan, Xiaohang and Liu, Ziwei and Ong, Yew Soon and Loy, Chen Change},
booktitle = {NeurIPS},
year = {2021}
}
Related
Projects
-
Delving into Inter-Image Invariance for Unsupervised Visual Representations
J. Xie, X. Zhan, Z. Liu, Y. S. Ong, C. C. Loy
Technical report, arXiv:2008.11702, 2020
[arXiv] [Project Page] -
Online Deep Clustering for Unsupervised Representation Learning
X. Zhan*, J. Xie*, Z. Liu, Y. S. Ong, C. C. Loy
in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2020 (CVPR)
[PDF] [arXiv] [Project Page]
