About
MMLab@NTU
MMLab@NTU is a research lab at Nanyang Technological University focused on advancing computer vision, multimodal AI, generative AI, and embodied AI. Founded in 2018, the lab has grown into a vibrant research group with around 40 members comprising faculty, research staff, and PhD students.
Our members develop both foundational methods and practical systems, with recent research covering areas such as large multimodal models, generative intelligence, 3D content creation, scene understanding, and efficient vision models for real-world deployment. The lab is committed to open research, impactful publications, and close engagement with the broader AI community. We welcome motivated PhD students, postdoctoral researchers, and research staff who are excited to push the frontier of visual intelligence.
CVPR 2026
06/2026: The team has a total of 8 papers (including 1 oral and 3 highlights) accepted to CVPR 2026. See you at Denver!
ICLR 2026
04/2026: The team has a total of 11 papers accepted to ICLR 2026. See you at Rio de Janeiro!
Google PhD Fellowship
10/2025: Yuekun and Ziang are awarded the very competitive and prestigious Google PhD Fellowship 2025 under the area “Machine Perception". Congrats!
CCDS Outstanding PhD Thesis Award
06/2026: Congratulations to Zhaoxi Chen on being named the recipient of CCDS’s Outstanding PhD Thesis Award 2026 for his thesis on multimodal neural 3D asset synthesis, and to Jianyi Wang on receiving an Honourable Mention for his work on harnessing foundation models for visual content restoration and quality assessment.
MMLAB@NTU
News and Highlights
- 06/2026: DynamicVLA received the CVPR 2026 GigaBrain Workshop Best Paper Award. Congrats!
- 06/2026: EgoLife received the EgoVis 2024/2025 Distinguished Paper Award. Congrats!
- 04/2026: Ziang Cao received the Rising Star Award at China3DV 2026. PhysX-Anything by Ziang is also selected as one of the Top-5 Papers at China3DV. Congrats!
- 11/2025: Penghao Wu is awarded the ByteDance PhD Fellowship 2025. Congrats!
- 10/2025: Congratulations to Shangchen Zhou on being named a joint recipient of CCDS’s Outstanding PhD Thesis Award 2025 for his thesis on visual content restoration and enhancement, and to Yuming Jiang on receiving an Honourable Mention for his work on controllable image and video synthesis.
- 10/2025: The team has a total of 16 papers accepted to ICCV 2025.
- 06/2025: The team has a total of 20 papers (including 2 orals and 3 highlights) accepted to CVPR 2025.
- 03/2025: Congratulations to Ziqi Huang on being named a 2025 Apple Scholar in AIML, a highly competitive PhD fellowship that recognizes innovative research, leadership, and impact. Apple highlighted Ziqi’s work in human-machine collaborative visual generation and editing at NTU. Congrats!
- 02/2025: Yushi Lan and Zhaoxi Chen received Outstanding Prize from the Meshy Fellowship Program 2025. Congrats!
Introducing Xperience-10M
The Largest Human Xperience Dataset for Physical AI
A large-scale egocentric multimodal dataset with 10 million experiences, 10,000 hours of synchronized first-person data, and rich annotations spanning video, audio, depth, pose, motion capture, IMU, and language. Built for embodied AI, robotics, world models, and spatial intelligence. Check the our project page for more information.
By Ropedia
Our MMLab@NTU startup, providing solutions for physical 4D intelligence — capture, structure, and model human experience at scale.
Featured
Projects

DynamicVLA: A Vision-Language-Action Model for Dynamic Object Manipulation
H. Xie, B. Wen, J. Zheng, Z. Chen, F. Hong, H. Diao, Z. Liu
Technical report, arXiv:2601.22153, 2026 (CVPR 2026 GigaBrain Workshop Best Paper Award)
[arXiv]
[Project Page]
DynamicVLA is a compact 0.4B vision-language-action model for dynamic object manipulation, designed to handle fast-moving objects by combining low-latency temporal reasoning with Continuous Inference and Latent-aware Action Streaming, which reduce perception–execution delays and enable smoother closed-loop control; the work also introduces the DOM benchmark, built with a scalable data pipeline spanning 200K synthetic episodes, 2.8K scenes, 206 objects, and 2K real-world episodes.

VLANeXt: Recipes for Building Strong VLA Models
X. M. Wu, B. Fan, K. Liao, J. J. Jiang, R. Yang, Y. Luo, Z. Wu, W. S. Zheng, C. C. Loy
in Proceedings of International Conference on Machine Learning, 2026 (ICML)
[arXiv]
[Project Page]
VLANeXt systematically studies the design space of vision–language–action (VLA) models and distills practical recipes for building strong robotic policies. By analyzing key components across perception, foundation backbones, and action modeling, it proposes a unified framework that improves task success and generalization on robotic manipulation benchmarks.

4RC: 4D Reconstruction via Conditional Querying Anytime and Anywhere
Y. Luo, S. Zhou, Y. Lan, X. Pan, C. C. Loy
in Proceedings of International Conference on Machine Learning, 2026 (ICML)
[arXiv]
[Project Page]
4RC is a unified feed-forward framework for 4D reconstruction from monocular videos. It learns a compact spatio-temporal latent representation that jointly models scene geometry and motion, enabling an encode-once, query-anytime paradigm to recover dense 3D structure and motion between arbitrary frames and timestamps efficiently.

Thinking with Camera: A Unified Multimodal Model for Camera-Centric Understanding and Generation
K. Liao, S. Wu, Z. Wu, L. Jin, C. Wang, Y. Wang, F. Wang, W. Li, C. C. Loy
International Conference on Learning Representations, 2026 (ICLR)
[PDF]
[arXiv]
[Project Page]
[Demo]
Puffin is a camera-centric multimodal model that unifies camera understanding and controllable image generation. By treating camera parameters as language tokens, it aligns geometric reasoning with vision–language models, enabling spatially consistent cross-view generation, camera reasoning, and scene exploration. The model is trained on Puffin-4M, a large dataset of vision–language–camera triplets.

STream3R: Scalable Sequential 3D Reconstruction with Causal Transformer
Y. Lan, Y. Luo, F. Hong, S. Zhou, H. Chen, Z. Lyu, S. Yang, B. Dai, C. C. Loy, X. Pan
International Conference on Learning Representations, 2026 (ICLR)
[arXiv]
[Project Page]
STream3R reformulates multi-view 3D reconstruction as a streaming Transformer problem. Using causal attention and feature caching across frames, it incrementally reconstructs dense scene geometry from image streams, enabling scalable and efficient online 3D perception. The model learns geometric priors from large-scale 3D data and achieves strong performance on both static and dynamic scenes.

Light-X : Generative 4D Video Rendering with Camera and Illumination Control
T. Liu, Z. Chen, Z. Huang, S. Xu, S. Zhang, C. Ye, B. Li, Z. Cao, W. Li, H. Zhao, Z. Liu
International Conference on Learning Representations, 2026 (ICLR)
[arXiv]
[Project Page]
Light-X is a controllable 4D video generation framework that renders videos from monocular input with joint control over camera trajectory and illumination, supporting effects such as bullet time, dolly zoom, and text-guided relighting; by disentangling geometry and lighting cues, it produces more temporally consistent and realistic results than prior video relighting and novel-view methods.
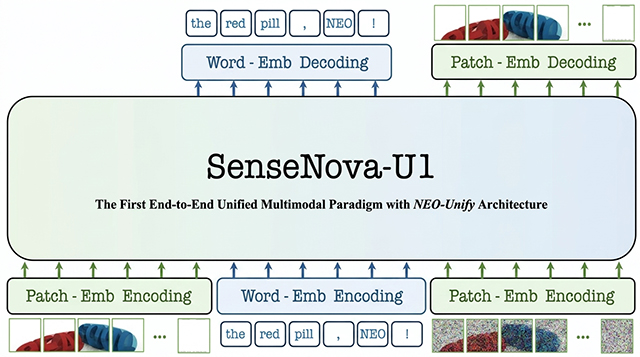
SenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
H. Diao, P. Wu, H. Deng, J. Wang, S. Bai, S. Wu, W. Fan et al.
Technical report, arXiv:2605.12500, 2026
[arXiv]
[Project Page]
[Demo]
We present SenseNova-U1, a unified multimodal model designed to bridge visual understanding and generation within a single native architecture. Built on the proposed NEO-unify framework, SenseNova-U1 enables strong performance across vision-language reasoning, spatial intelligence, agentic decision-making, and image generation tasks. The model supports capabilities such as text-rich image generation, interleaved vision-language generation, and emerging vision-language-action behaviors, pointing toward more general-purpose multimodal systems. Overall, SenseNova-U1 represents a step toward unified AI models that can understand, reason, generate, and act across modalities.
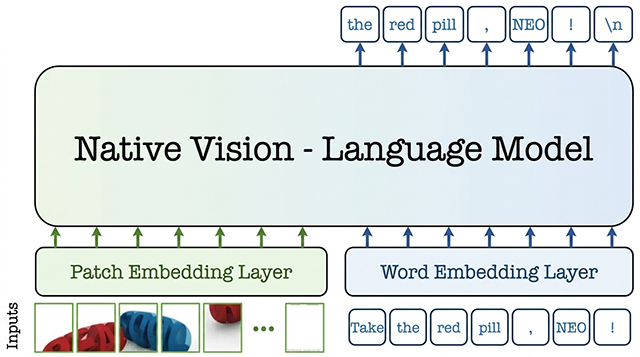
From Pixels to Words - Towards Native Vision-Language Primitives at Scale
H. Diao, M. Li, S. Wu, L. Dai, X. Wang, H. Deng, L. Lu, D. Lin, Z. Liu
International Conference on Learning Representations, 2026 (ICLR)
[arXiv]
[Project Page]
NEO is a family of native vision-language models built from first principles to unify pixel-word encoding, alignment, and reasoning within a single dense architecture, rather than relying on separate vision and language modules. It is designed to narrow the gap between native and modular VLMs, showing strong visual perception learned from scratch with 390M image-text examples, while providing an open and extensible foundation for scalable native multimodal model development.
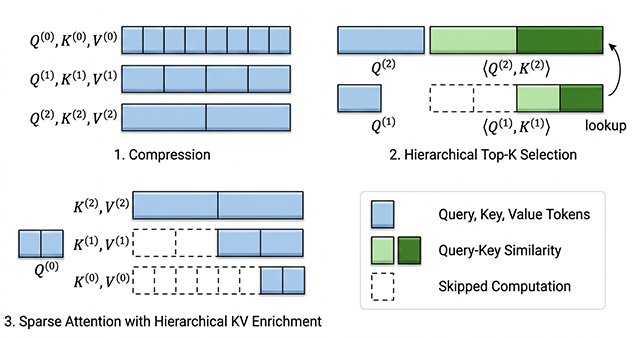
Trainable Log-linear Sparse Attention for Efficient Diffusion Transformers
Y. Zhou, Z. Xiao, T. Wei, S. Yang, X. Pan
in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2026 (CVPR, Highlight)
[arXiv]
[Project Page]
We introduce Log-linear Sparse Attention (LLSA), a trainable sparse attention mechanism that scales Diffusion Transformers to extremely long token sequences by replacing quadratic attention with a log-linear hierarchical design; through hierarchical Top-K selection, hierarchical key–value enrichment, and an efficient sparse-index GPU implementation, it substantially improves efficiency while maintaining generation quality, achieving up to 28.27× faster attention inference and 6.09× faster DiT training on 256×256 pixel-token sequences.

PhysX-Anything: Simulation-Ready Physical 3D Assets from Single Image
Z. Cao, F. Hong, Z. Chen, L. Pan, Z. Liu
in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2026 (CVPR)
[arXiv]
[Project Page]
PhysX-Anything generates simulation-ready physical 3D assets from a single image, producing not just shape but also explicit geometry, articulation, and physical attributes so the assets can be used directly in simulation and embodied AI; it also introduces a more efficient geometry representation and the PhysX-Mobility dataset with 2K+ real-world objects to support this task.

MatAnyone2: Scaling Video Matting via a Learned Quality Evaluator
P. Yang, S. Zhou, K. Hao, Q. Tao
in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2026 (CVPR, Highlight)
[arXiv]
[Project Page]
[Demo]
MatAnyone 2 is a practical video matting framework that improves robustness in real-world scenes while preserving fine boundary details such as hair and motion blur. It introduces a learned Matting Quality Evaluator (MQE) to estimate matte quality without ground truth, enabling both better training supervision and large-scale data curation. Using this idea, we build VMReal, a large real-world video matting dataset with 28K clips and 2.4M frames, and further improve temporal robustness with a reference-frame training strategy for long videos.
Read
Blog Posts
NEO-unify: Building Native Multimodal Unified Models End to End
For years, multimodal AI typically adopts a vision encoder (VE) to perceive and a variational autoencoder (VAE) to generate. Recent efforts seek to unify both with a shared tokenizer — but often with trade-offs. We return to the first principles: Building a model that directly engages with native inputs — pixels and words.
Haiwen Diao
Mar 5, 2026