Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data
NeurIPS 2021
Paper
Abstract
Generative adversarial networks (GANs) typically require ample data for training in order to synthesize high-fidelity images. Recent studies have shown that training GANs with limited data remains formidable due to discriminator overfitting, the underlying cause that impedes the generator's convergence. This paper introduces a novel strategy called Adaptive Pseudo Augmentation (APA) to encourage healthy competition between the generator and the discriminator. As an alternative method to existing approaches that rely on standard data augmentations or model regularization, APA alleviates overfitting by employing the generator itself to augment the real data distribution with generated images, which deceives the discriminator adaptively. Extensive experiments demonstrate the effectiveness of APA in improving synthesis quality in the low-data regime. We provide a theoretical analysis to examine the convergence and rationality of our new training strategy. APA is simple and effective. It can be added seamlessly to powerful contemporary GANs, such as StyleGAN2, with negligible computational cost.

StyleGAN2 synthesized results (no truncation) deteriorate given the limited amount of training data (256 × 256), i.e., FFHQ (a subset of 5,000 images, ~7% of full data), AFHQ-Cat (5,153 images, which is small by itself), and Danbooru2019 Portraits (Anime) (a subset of 5,000 images, ∼2% of full data). The proposed Adaptive Pseudo Augmentation (APA) effectively ameliorates the degraded performance of StyleGAN2 on limited data.
The training of StyleGAN2 diverge rapidly on FFHQ-7k (a subset of 7,000 images, 10% of full data), as shown by the generated examples and the FID curve. The proposed APA effectively improves the training convergence of StyleGAN2 on limited data.
Methodology
Adaptive Pseudo Augmentation (APA)
We find that the generator itself naturally possesses the capability to counteract the discriminator overfitting that impedes effective GAN training on limited data. Without introducing any external augmentations or regularization terms, we employ a GAN to augment itself using the generated images to deceive the discriminator adaptively. Specifically, APA feeds the fake/pseudo samples synthesized by the generator into the limited real data moderately, and these pseudo data are presented as “real” instances to the discriminator. Such deceits are introduced adaptively using an overfitting heuristic λ defined by the discriminator raw output logits. The augmentation/deception probability p can be adaptively controlled throughout training.
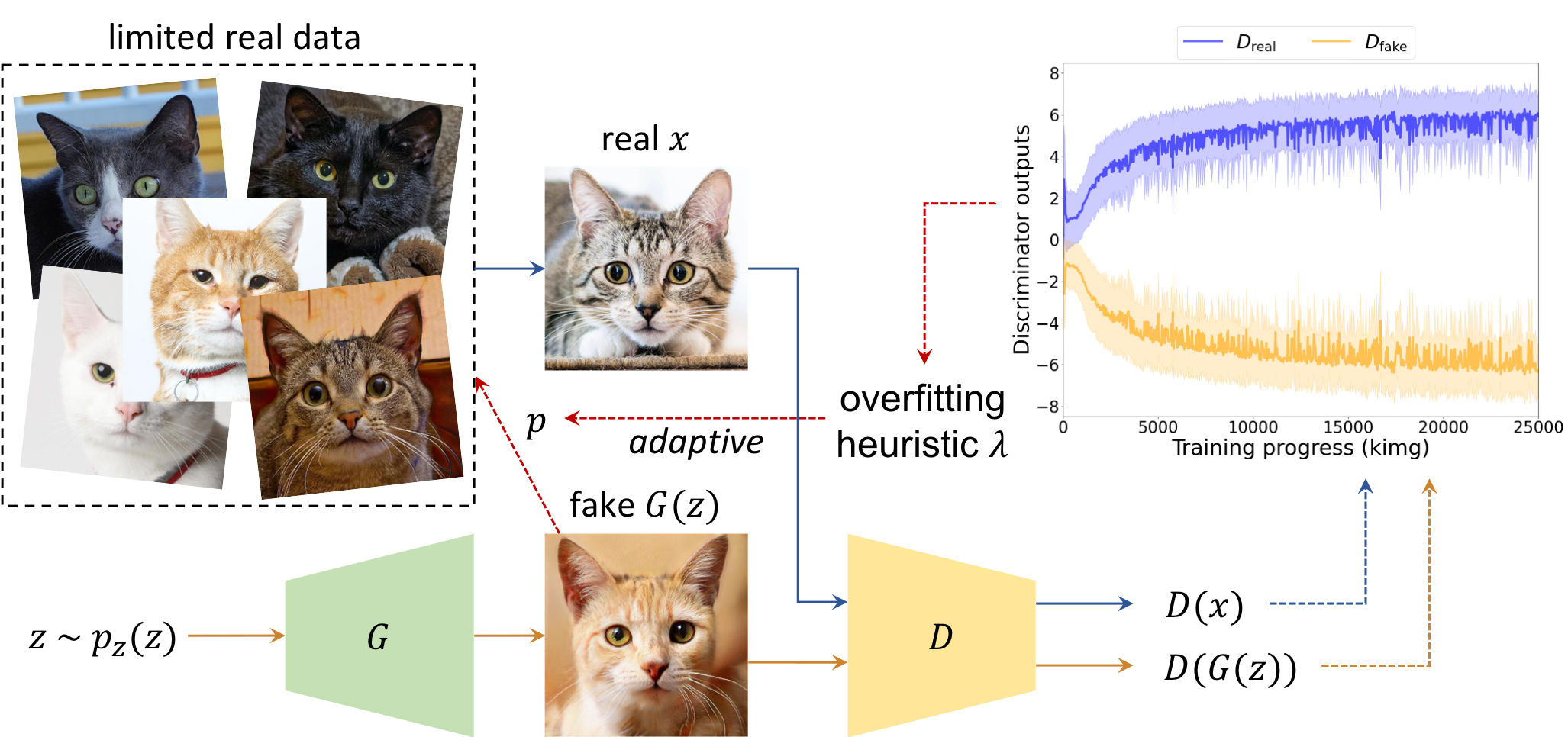
Effectiveness
on Various Datasets
The quality of images (256 × 256, no truncation) synthesized by state-of-the-art StyleGAN2 degrades under limited data. Ripple artifacts appear on the cat faces and human faces, and the facial features of the anime faces are misplaced. On the bird dataset with heavy background clutter, the generated images are completely distorted although trained with more data. The proposed APA significantly ameliorates image quality on all these datasets, producing much more photorealistic results.

Effectiveness
Given Different Data Amounts
Below we show comparative results on subsets (256 × 256, no truncation) of FFHQ with varying amounts of data. APA improves the image quality in all cases. Notably, the quality of synthesized images by APA on 5k and 7k data is visually close to StyleGAN2 results on the full dataset while with an order of magnitude fewer training samples.

Effectiveness
Overfitting and Convergence Analysis
We further provide the overfitting and convergence analysis of APA compared to StyleGAN2 (SG2) on FFHQ (256 × 256). The divergence of StyleGAN2 discriminator predictions can be effectively restricted on FFHQ-7k (10% data) by applying the proposed APA. The curves of APA on FFHQ-7k become closer to that of StyleGAN2 on FFHQ-70k, suggesting the effectiveness of APA in curbing the overfitting of the discriminator. Besides, APA improves the training convergence of StyleGAN2 on limited data, shown by the FID curves.
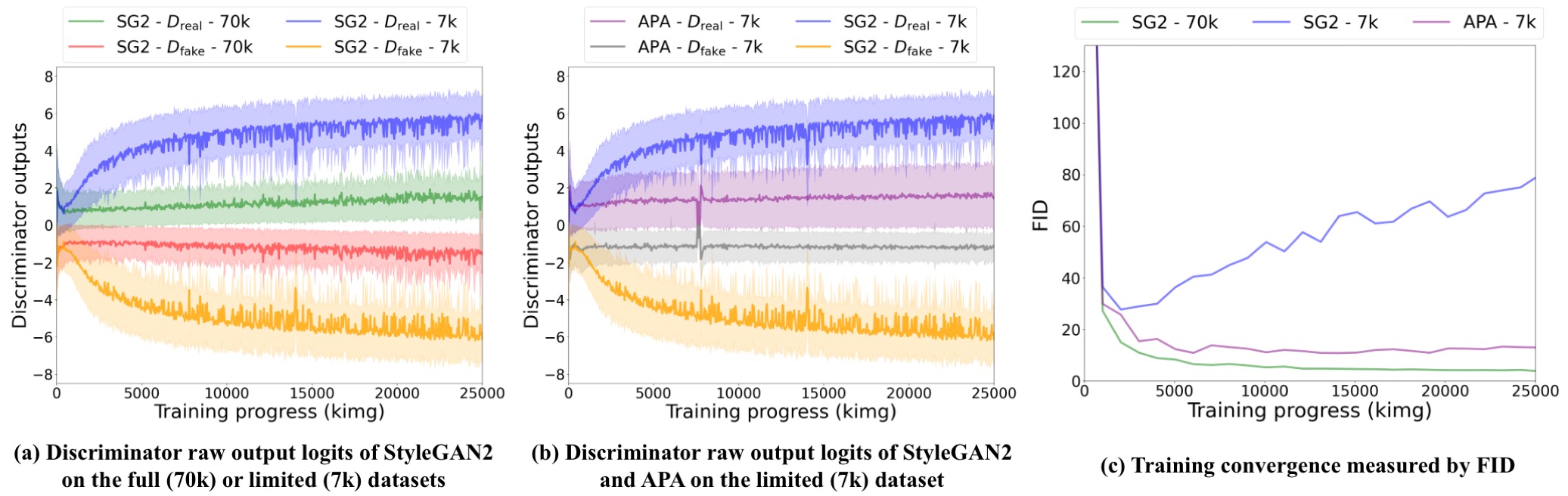
Comparison
with Other State-of-the-Art Solutions
The proposed APA achieves comparable or even better visual quality than other state-of-the-art approaches designed for GAN training with limited data, including ADA and LC-regularization (LC-Reg). Notably, APA is also complementary to ADA for gaining a further performance boost, suggesting the compatibility of our method with standard data augmentations. Meanwhile, the training cost of APA is much less than ADA, indicating the advantage of APA on negligible computational cost (details can be found in our paper).

Higher-Resolution
Additional Results
We further show the effectiveness of APA to improve StyleGAN2 higher-resolution synthesized results (1024 × 1024, no truncation) trained with limited data, i.e., FFHQ-5k (∼7% data). Our method achieves an FID score of 9.545, outperforming the original StyleGAN2 of 18.296.

Paper
Citation
@inproceedings{jiang2021DeceiveD,
title={{Deceive D: Adaptive Pseudo Augmentation} for {GAN} Training with Limited Data},
author={Jiang, Liming and Dai, Bo and Wu, Wayne and Loy, Chen Change},
booktitle={NeurIPS},
year={2021}
}
Related
Projects
-
Focal Frequency Loss for Image Reconstruction and Synthesis
L. Jiang, B. Dai, W. Wu, C. C. Loy
in Proceedings of IEEE/CVF International Conference on Computer Vision, 2021 (ICCV)
[PDF] [arXiv] [Supplementary Material] [Project Page] [YouTube] -
TSIT: A Simple and Versatile Framework for Image-to-Image Translation
L. Jiang, C. Zhang, M. Huang, C. Liu, J. Shi, C. C. Loy
European Conference on Computer Vision, 2020 (ECCV, Spotlight)
[PDF] [arXiv] [Supplementary Material] [Project Page]
