Dense Siamese Network for Dense Unsupervised Learning
ECCV 2022
Paper
Abstract
We present Dense Siamese Network (DenseSiam), a simple unsupervised learning framework for dense prediction tasks. It learns visual representations by maximizing the similarity between two views of one image with two types of consistency, i.e., pixel consistency and region consistency. Concretely, DenseSiam first maximizes the pixel level spatial consistency according to the exact location correspondence in the overlapped area. It also extracts a batch of region embeddings that correspond to some sub-regions in the overlapped area to be contrasted for region consistency. In contrast to previous methods that require negative pixel pairs, momentum encoders or heuristic masks, DenseSiam benefits from the simple Siamese network and optimizes the consistency of different granularities. It also proves that the simple location correspondence and interacted region embeddings are effective enough to learn the similarity. We apply DenseSiam on ImageNet and obtain competitive improvements on various downstream tasks. We also show that only with some extra task-specific losses, the simple framework can directly conduct dense prediction tasks. On an existing unsupervised semantic segmentation benchmark, it surpasses state-of-the-art segmentation methods by 2.1 mIoU with 28% training costs.
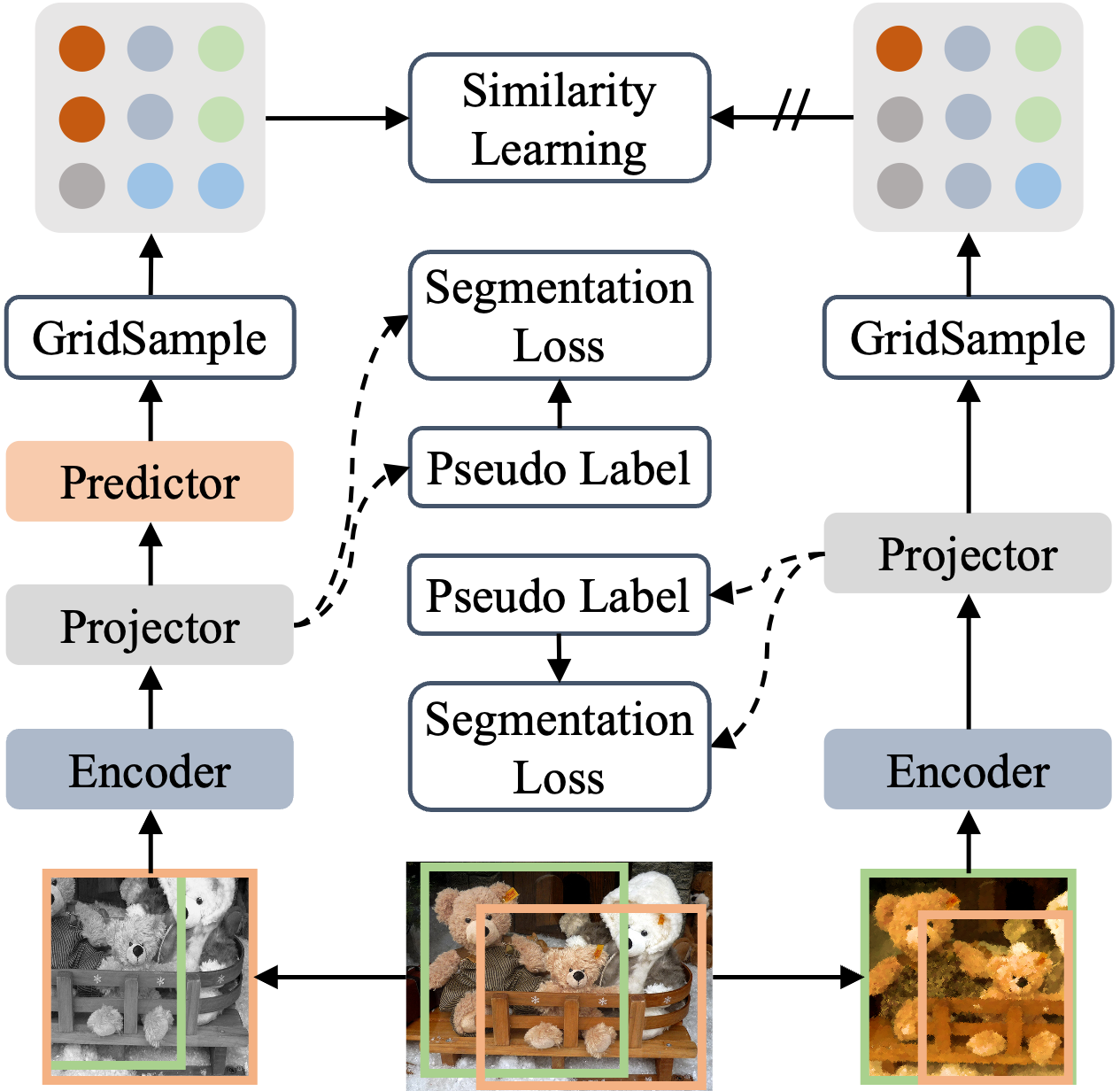
DenseSiam unanimously solves unsupervised pretraining and unsupervised semantic segmentation. The pair of images are first processed by the same encoder network and a convolutional projector. Then a predictor is applied on one side, and a stop-gradient operation on the other side. A grid sampling method is used to extract dense predictions in the overlapped area. DenseSiam can perform unsupervised semantic segmentation by simply adding a segmentation loss with pseudo labels produced by the projector.
Framework
DenseSiam
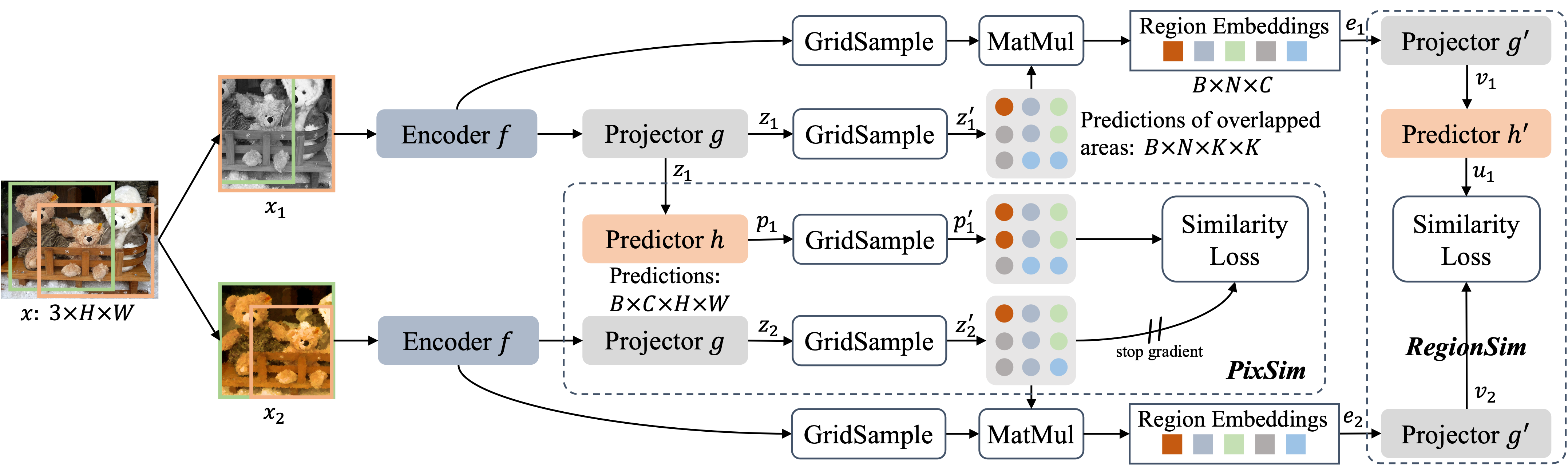
DenseSiam takes two randomly augmented views of an image as inputs. The two views are processed by an encoder network without global average pooling (GAP), followed by a projector network. The predictor network transforms the dense prediction of the projector of one view. Then GridSample module samples the same pixels inside the intersected regions of the two views and interpolates their feature grids. The similarity between feature grids from two views are maximized by PixSim. Then DenseSiam multiplies the features of encoder and the dense predictions by projector in the overlapped area to obtain region embeddings of each image. These region embeddings are processed by a new projector and new predictor for region level similarity learning.
Experimental
Results
Table 1: Results of transfer learning.
| Pre-train | COCO Instance Segmentation | COCO Object Detection | Cityscapes | VOC 07+12 Detection | ||||||
| Mask AP | Mask AP50 | Mask AP75 | Bbox AP | Bbox AP50 | Bbox AP75 | mIoU | Bbox AP | Bbox AP50 | Bbox AP75 | |
| scratch | 29.9 | 47.9 | 32.0 | 32.8 | 50.9 | 35.3 | 63.5 | 32.8 | 59.0 | 31.6 |
| supervised | 35.9 | 56.6 | 38.6 | 39.7 | 59.5 | 43.3 | 73.7 | 54.2 | 81.6 | 59.8 |
| BYOL [1] | 34.9 | 55.3 | 37.5 | 38.4 | 57.9 | 41.9 | 71.6 | 51.9 | 81.0 | 56.5 |
| SimCLR [2] | 34.8 | 55.2 | 37.2 | 38.5 | 58.0 | 42.0 | 73.1 | 51.5 | 79.4 | 55.6 |
| MoCo v2 [3] | 36.1 | 56.9 | 38.7 | 39.8 | 59.8 | 43.6 | 74.5 | 57.0 | 82.4 | 63.6 |
| SimSiam [4] | 36.4 | 57.4 | 38.8 | 40.4 | 60.4 | 44.1 | 76.3 | 56.7 | 82.3 | 63.4 |
| ReSim [5] | 36.1 | 56.7 | 38.8 | 40.0 | 59.7 | 44.3 | 76.8 | 58.7 | 83.1 | 66.3 |
| DetCo [6] | 36.4 | 57.0 | 38.9 | 40.1 | 60.3 | 43.9 | 76.5 | 57.8 | 82.6 | 64.2 |
| DenseCL [7] | 36.4 | 57.0 | 39.2 | 40.3 | 59.9 | 44.3 | 75.7 | 58.7 | 82.8 | 65.2 |
| PixPro [8] | 36.6 | 57.3 | 39.1 | 40.5 | 60.1 | 44.3 | 76.3 | 59.5 | 83.4 | 66.9 |
| DenseSiam (ours) | 36.8 | 57.6 | 39.8 | 40.8 | 60.7 | 44.6 | 77.0 | 58.5 | 82.9 | 65.3 |
Table 2: Results of unsupervised semantic segmentation.
| Method | mIoU | mIoUSt | mIoUTh | Time (h) |
| Modified Deep Clustering [9] | 9.8 | 22.2 | 11.6 | - |
| IIC [10] | 6.7 | 12.0 | 13.6 | - |
| PiCIE + auxiliary head [11] | 14.4 | 17.3 | 23.8 | 18 |
| DenseSiam + auxiliary head (ours) | 16.4 | 24.5 | 29.5 | 5 |
[1] Bootstrap your own latent - A new approach to self-supervised learning, NeurIPS
2020.
[2] A simple framework for contrastive learning of visual representations, ICML
2020.
[3] Improved baselines with momentum contrastive learning, CoRR abs/2003.04297.
[4] Exploring simple siamese representation learning, CVPR 2021.
[5] Region similarity representation
learning, ICCV 2021.
[6] Unsupervised
contrastive learning for object detection, ICCV 2021.
[7] Dense contrastive learning for
self-supervised visual pre-training, CVPR 2021.
[8] Propagate yourself: Exploring
pixel-level consistency for unsupervised visual representation learning, CVPR 2021.
[9] Deep clustering for unsupervised
learning of visual features, ECCV 2018.
[10] Invariant information clustering for unsupervised
image classification and segmentation, ICCV2019.
[11] PiCIE: Unsupervised semantic segmentation
using invariance and equivariance in clustering, CVPR 2021.
Paper
Citation
@inproceedings{zhang2022densesiam,
author = {Wenwei Zhang and Jiangmiao Pang and Kai Chen and Chen Change Loy},
title = {Dense Siamese Network for Dense Unsupervised
Learning},
year = {2022},
booktitle = {ECCV},
}
Related
Projects
-
K-Net: Towards Unified Image Segmentation
W. Zhang, J. Pang, K. Chen, C. C. Loy
in Proceedings of Neural Information Processing Systems, 2021 (NeurIPS)
[PDF] [Project Page] [Code] -
Unsupervised Object-Level Representation Learning from
Scene Images
J. Xie, X. Zhan, Z. Liu, Y. S. Ong, C. C. Loy
in Proceedings of Neural Information Processing Systems, 2021 (NeurIPS) 2021(NeurIPS)
[PDF] [arXiv] [Project Page]
