StyleGANEX: StyleGAN-Based Manipulation Beyond Cropped Aligned Faces
Paper
Abstract
Recent advances in face manipulation using StyleGAN have produced impressive results. However, StyleGAN is inherently limited to cropped aligned faces at a fixed image resolution it is pre-trained on. In this paper, we propose a simple and effective solution to this limitation by using dilated convolutions to rescale the receptive fields of shallow layers in StyleGAN, without altering any model parameters. This allows fixed-size small features at shallow layers to be extended into larger ones that can accommodate variable resolutions, making them more robust in characterizing unaligned faces. To enable real face inversion and manipulation, we introduce a corresponding encoder that provides the first-layer feature of the extended StyleGAN in addition to the latent style code. We validate the effectiveness of our method using unaligned face inputs of various resolutions in a diverse set of face manipulation tasks, including facial attribute editing, super-resolution, sketch/mask-to-face translation, and face toonification.

The
StyleGANEX Architecture
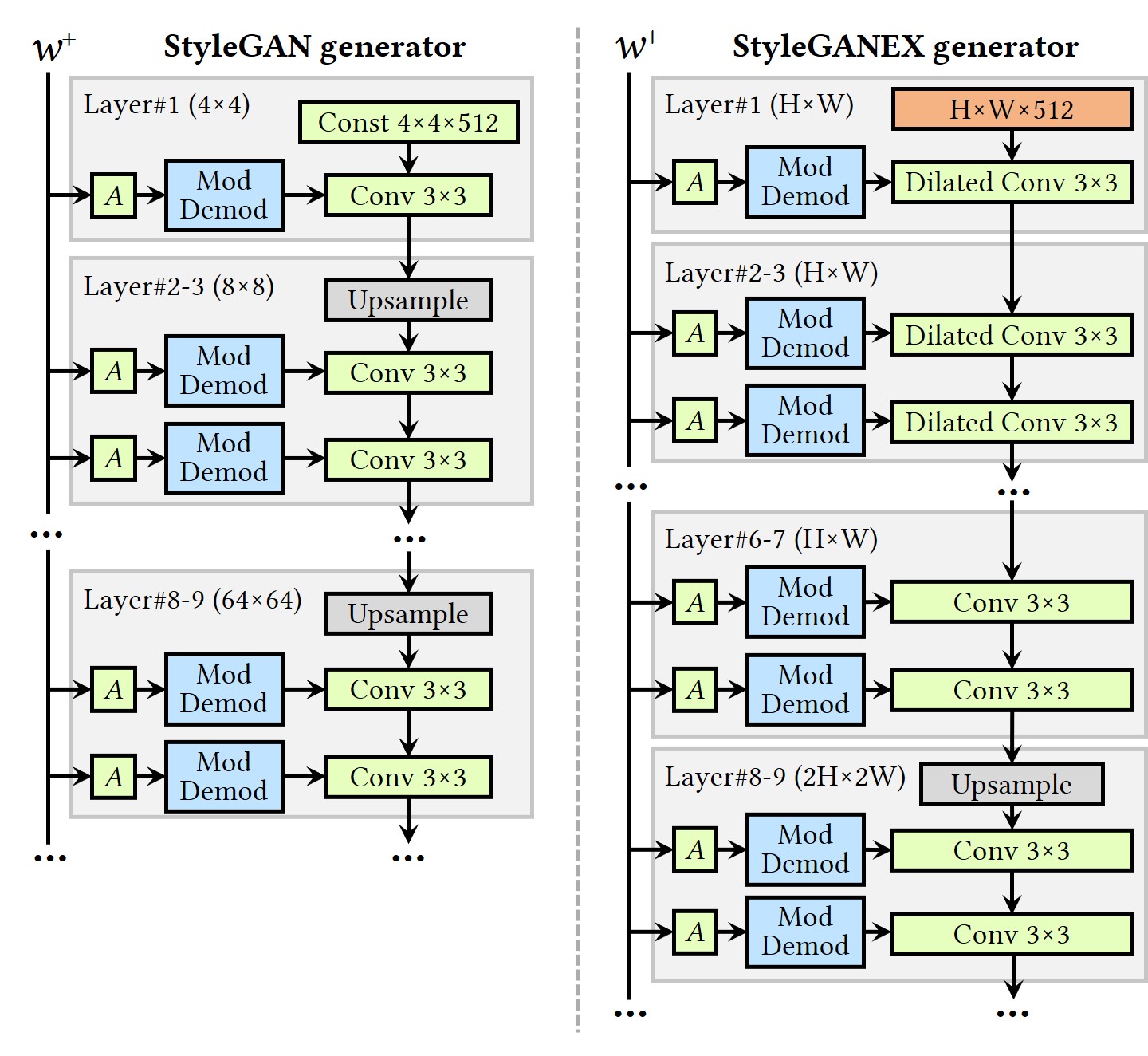
The generative space of StyleGAN has a fatal fixed-crop limitation: the resolution of the image and the layout of the face in the image are fixed. To overcome this limitation, we refactor the shallow layers of StyleGAN to make its first layer accept input features of any resolution and enlarge the reception fields of these layers to match the input features by simply modifying the convolutions to their dilated versions. It expands StyleGAN's style latent space into a more powerful joint style latent and first-layer feature space, extending the generative space beyond cropped aligned faces. The refactoring has three advantages. 1) Support for unaligned faces The resolution enlargement and variable first-layer features overcome the fixed-cropped limitation, enabling the manipulation of normal FoV face images and videos. 2) Compatibility No model parameters are altered during refactoring, meaning that StyleGANEX can directly load a pre-trained StyleGAN parameters without retrainings. 3) Flexible manipulation StyleGANEX retains the style representation and editing ability of StyleGAN, meaning that abundant StyleGAN-based face manipulation techniques can be applied to StyleGANEX.
Applications of
StyleGANEX
Equiped with a StyleGANEX encoder to provide the style code and the first-layer feature for StyleGANEX, we can perform a diverse set of face manipulation tasks on normal field-of-view face images/videos, including facial attribute editing, face super-resolution, sketch/mask-to-face translation and video face toonification.
Experimental
Results
Overview of StyleGANEX inversion and facial attribute/style editing

We apply inversion to normal FoV face photos/paintings, and use the editing vectors from InterFaceGAN and LowRankGAN, as well as the pre-trained StyleGAN-NADA Ukiyo-e model to edit the facial attributes or styles. As shown, these StyleGAN editing techniques work well on StyleGANEX.
Comparison with state-of-the-art face manipulation methods
Image face editing

We perform visual comparison with pSp and HyperStyle. Since the compared baselines are designed for cropped aligned faces, we paste and blend their edited results back to the original image. Latent optimization is applied to pSp and our StyleGANEX encoder for precise inversion before editing (HyperStyle already uses extra hyper networks to simulate optimization). For editing that alters structures or colors, even a precise inversion and blending cannot eliminate the obvious discontinuity along the seams, as pointed by yellow arrows. In contrast, our approach processes the entire image as a whole and avoids such issues. Remarkably, our method successfully turns the whole hair into black in (b), transfers the exemplar blond hairstyle onto the target face in (c), and renders the full background with the StyleGAN-NADA Edvard Munch style in (d), while other methods fail to produce satisfactory results.
Video facial attribute editing
As with image face editing, the results of pSp and HyperStyle have discontinuity near the seams. In addition, the latent code alone cannot ensure temporal consistency in videos. By comparison, our method uses the first-layer feature and skipped mid-layer features to provide spatial information, which achieves more coherent results.
Video face toonification
Compared with VToonify-T, our method preserves more details of the non-face region and generates shaper faces. The reason is that VToonify-T uses a fixed latent code extractor while our method trains a joint latent code and feature extractor, thus our method is more powerful for reconstructing the details. Moreover, our method retains StyleGAN's shallow layers, which helps provide key facial features to make the stylized face more vivid.
Paper
Citation
@InProceedings{yang2023styleganex,
title = {StyleGANEX: StyleGAN-Based Manipulation Beyond Cropped Aligned Faces},
author = {Yang, Shuai and Jiang, Liming and Liu, Ziwei and and Loy, Chen Change},
booktitle = {ICCV},
year = {2023},
}
Related
Projects
-
VToonify: Controllable High-Resolution Portrait Video Style Transfer
S. Yang, L. Jiang, Z. Liu, C. C. Loy
ACM Transactions on Graphics, 2022 (SIGGRAPH Asia - TOG)
[PDF] [arXiv] [Project Page] -
Pastiche Master: Exemplar-Based High-Resolution Portrait Style Transfer
S. Yang, L. Jiang, Z. Liu, C. C. Loy
in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2022 (CVPR)
[PDF] [arXiv] [Project Page] -
Deep Plastic Surgery: Robust and Controllable Image Editing with Human-Drawn Sketches
S. Yang, Z. Wang, J. Liu, Z. Guo
in Proceedings of European Conference on Computer Vision, 2020 (ECCV)
[PDF] [arXiv] [Project Page]
