Open-Vocabulary DETR with Conditional Matching
ECCV 2022, Oral
Paper
Abstract
Open-vocabulary object detection, which is concerned with the problem of detecting novel objects guided by natural language, has gained increasing attention from the community. Ideally, we would like to extend an open-vocabulary detector such that it can produce bounding box predictions based on user inputs in form of either natural language or exemplar image. This offers great flexibility and user experience for human-computer interaction. To this end, we propose a novel open-vocabulary detector based on DETR---hence the name OV-DETR---which, once trained, can detect any object given its class name or an exemplar image. The biggest challenge of turning DETR into an open-vocabulary detector is that it is impossible to calculate the classification cost matrix of novel classes without access to their labeled images. To overcome this challenge, we formulate the learning objective as a binary matching one between input queries (class name or exemplar image) and the corresponding objects, which learns useful correspondence to generalize to unseen queries during testing. For training, we choose to condition the Transformer decoder on the input embeddings obtained from a pre-trained vision-language model like CLIP, in order to enable matching for both text and image queries. With extensive experiments on LVIS and COCO datasets, we demonstrate that our OV-DETR---the first end-to-end Transformer-based open-vocabulary detector---achieves non-trivial improvements over current state of the arts.
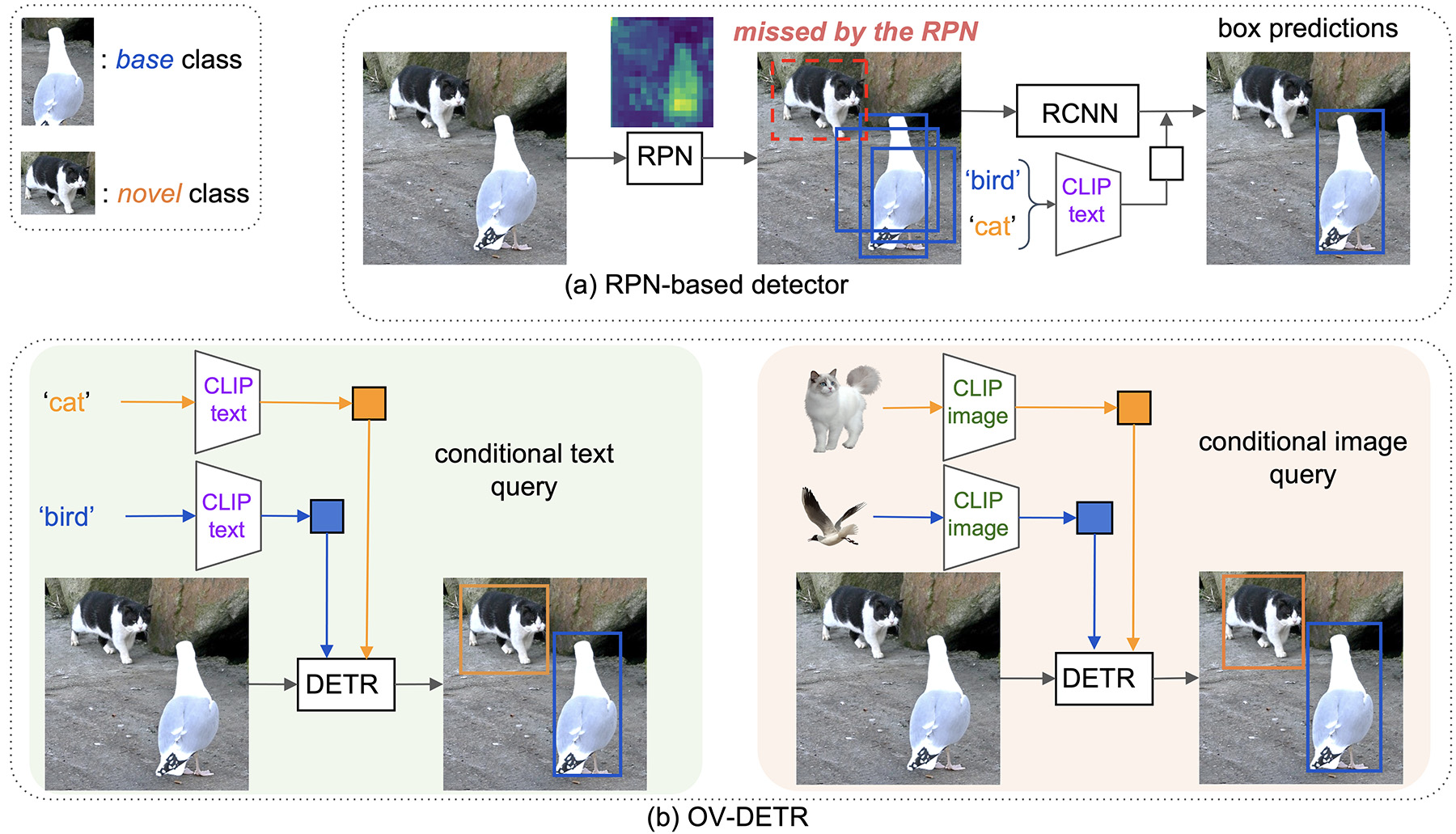
Comparison between a RPN-based detector and our Open-Vocabulary Transformer-based detector (OV-DETR) using conditional queries. The RPN trained on closed-set object classes tends to ignore novel classes (e.g., the `cat' region receives little response). Hence the cats in this example are largely missed with few to no proposals. By contrast, our OV-DETR is trained to perform matching between a conditional query and its corresponding box, which helps to learn correspondence that can generalize to queries from unseen classes. Note we can take input queries in the form of either text (class name) or exemplar images, which offers greater flexibility for open-vocabulary object detection.
The Framework
OV-DETR
We build on the success of DETR that casts object detection as an end-to-end set matching problem (among closed classes), thus eliminating the need of hand-crafted components like anchor generation and non-maximum suppression. We provide a new perspective on the matching task in DETR, which leads us to reformulate the fixed set-matching objective into a conditional binary matching one between conditional inputs (text or image queries) and detection outputs.
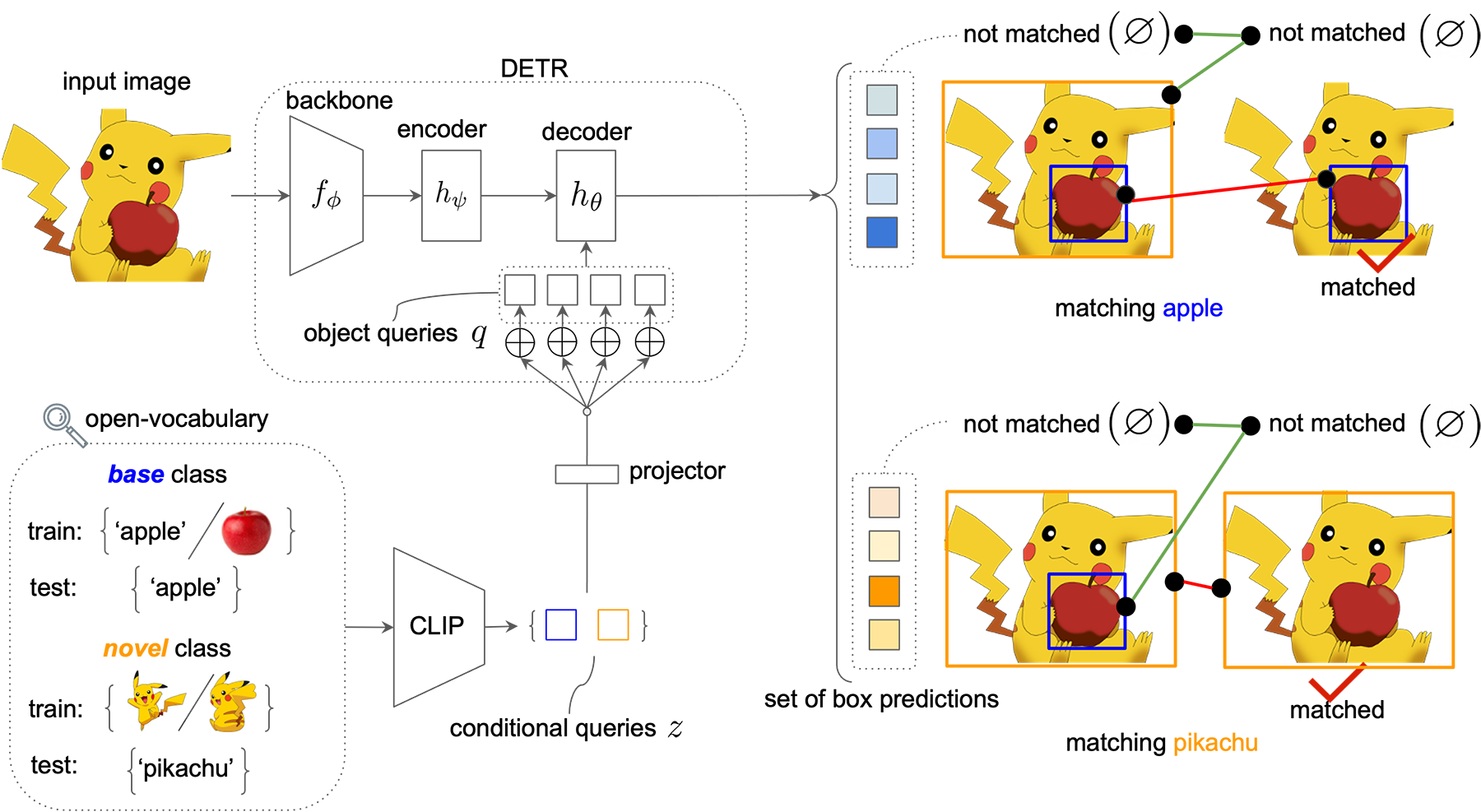
Overview of OV-DETR. Unlike the standard DETR, our method does not separate `objects' from `non-objects' for a closed set of classes. Instead, OV-DETR performs open-vocabulary detection by measuring the matchability (`matched' vs. `not matched') between some conditional inputs (text or exemplar image embeddings from CLIP) and detection results. We show such pipeline is flexible to detect open-vocabulary classes with arbitrary text or image inputs.
Experimental
Results
| Method | OV-LVIS | OV-COCO | |||||
|---|---|---|---|---|---|---|---|
| AP | APnovel | APc | APf | AP50 | AP50novel | AP50base | |
| SB [1] | - | - | - | - | 24.9 | 0.3 | 29.2 |
| DELO [2] | - | - | - | - | 13.0 | 3.1 | 13.8 |
| PL [3] | - | - | - | - | 27.9 | 4.1 | 35.9 |
| OVR-CNN [4] | - | - | - | - | 46.0 | 22.8 | 39.9 |
| ViLD-text [5] | 24.9 | 10.1 | 23.9 | 32.5 | 49.3 | 5.9 | 61.8 |
| ViLD [5] | 22.5 | 16.1 | 20.0 | 28.3 | 51.3 | 27.6 | 59.5 |
| ViLD-ensemble [5] | 25.5 | 16.6 | 24.6 | 30.3 | - | - | - |
| OV-DETR (ours) | 26.6 | 17.4 | 25.0 | 32.5 | 52.7 | 29.4 | 61.0 |
| Method | Pascal VOC | COCO | |||
|---|---|---|---|---|---|
| AP50 | AP75 | AP | AP50 | AP75 | |
| ViLD-text [5] | 40.5 | 31.6 | 28.8 | 43.4 | 31.4 |
| ViLD [5] | 72.2 | 56.7 | 36.6 | 55.6 | 39.8 |
| OV-DETR (ours) | 76.1 | 59.3 | 38.1 | 58.4 | 41.1 |
[1] Zero-shot Object Detection, ECCV 2020.
[2] Don’t Even Look Once: Synthesizing Features for Zero-Shot Detection, CVPR 2020.
[3] An Improved Attention for Visual Question Answering, CVPR 2021.
[4] Open-vocabulary Object Detection using Captions, CVPR 2021.
[5] Open-vocabulary Object Detection via Vision and Language Knowledge Distillation, ICLR 2022.
Result
Visualization
We show OV-DETR's detection and segmentation results. The results based on conditional text queries, conditional image queries, and a mixture of conditional text and image queries are shown in the top, middle and bottom row, respectively. Overall, our OV-DETR can accurately localize and precisely segment out the target objects from novel classes despite no annotations of these classes during training. It is worth noting that the conditional image queries, such as 'crape' in (d) and `fork' in (h), appear drastically different from those in the target images but OV-DETR can still robustly detect them.

Qualitative results on novel classes. OV-DETR can precisely detect and segment novel objects (e.g., `crape', `fishbowl', `softball') given the conditional text query (top) or conditional image query (middle) or a mixture of them (bottom).
We also visualize the activation maps of OV-DETR and Region Proposal Network (RPN) used by previous methods, which further validate the motivation from the main paper: OV-DETR has higher activation values on objects of novel classes than RPN.
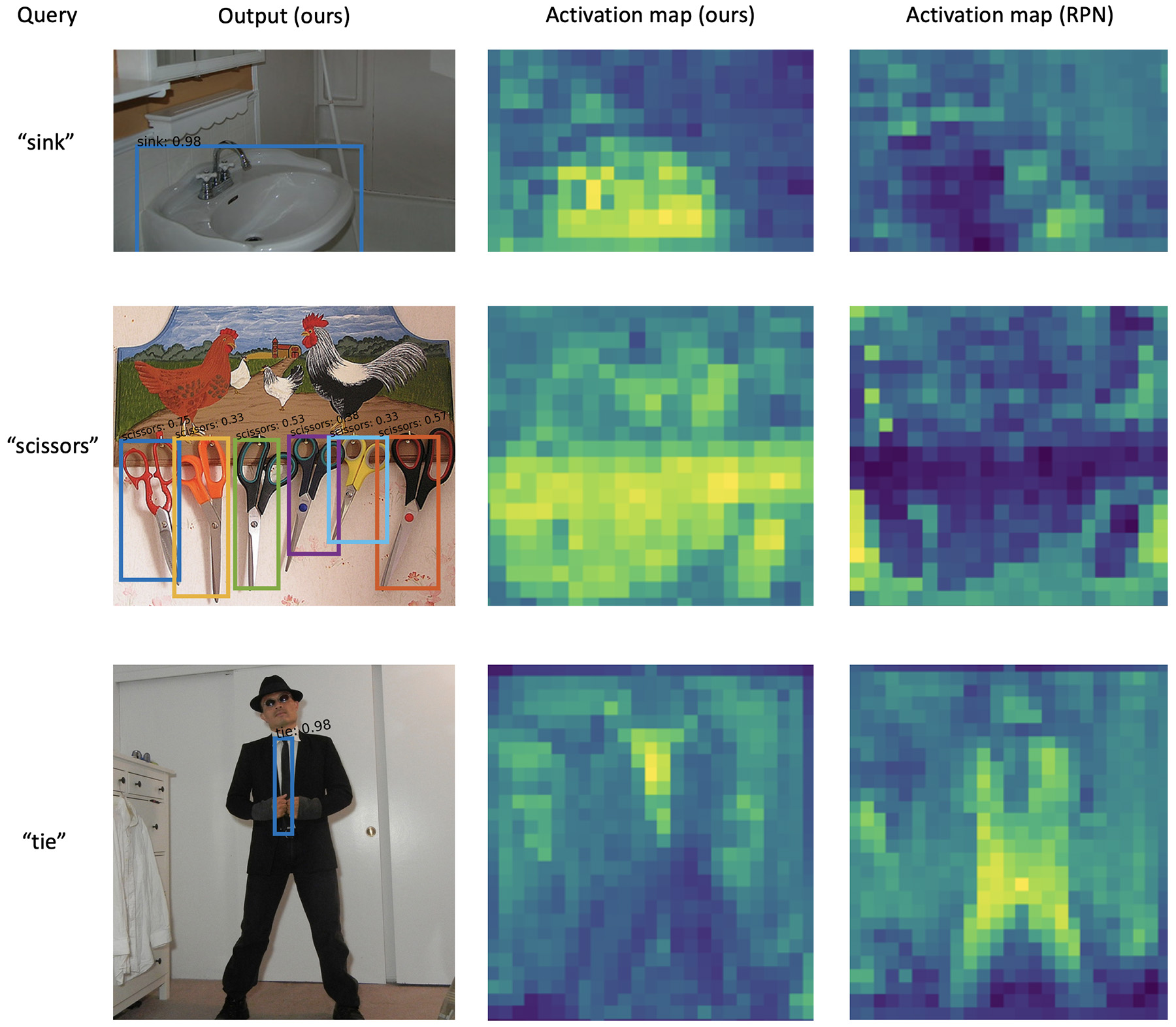
Qualitative results of activation maps. We also provide the comparison of activation maps between ours and the RPN network.
Paper
Citation
@InProceedings{zang2022open,
author = {Zang, Yuhang and Li, Wei and Zhou, Kaiyang and Huang, Chen and Loy, Chen Change},
title = {Open-Vocabulary DETR with Conditional Matching},
journal = {European Conference on Computer Vision},
year = {2022}
}
Related
Projects
-
FASA: Feature Augmentation and Sampling Adaptation for Long-Tailed Instance Segmentation
Y. Zang, C. Huang, C. C. Loy
in Proceedings of IEEE/CVF International Conference on Computer Vision, 2021 (ICCV)
[PDF] [arXiv] [Supplementary Material] [Project Page] -
K-Net: Towards Unified Image Segmentation
W. Zhang, J. Pang, K. Chen, C. C. Loy
in Proceedings of Neural Information Processing Systems, 2021 (NeurIPS)
[PDF] [arXiv] [Project Page] -
Seesaw Loss for Long-Tailed Instance Segmentation
J. Wang, W. Zhang, Y. Zang, Y. Cao, J. Pang, T. Gong, K. Chen, Z. Liu, C. C. Loy, D. Lin
in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2021 (CVPR)
[PDF] [Supplementary Material] [arXiv] [Code]
