Papers
ECCV 2022

Extract Free Dense Labels from CLIP
C. Zhou, C. C. Loy, B. Dai
European Conference on Computer Vision, 2022 (ECCV, Oral)
[PDF]
[arXiv]
[Supplementary Material]
[Project Page]
We examine the intrinsic potential of CLIP for pixel-level dense prediction, specifically in semantic segmentation. With minimal modification, we show that MaskCLIP yields compelling segmentation results on open concepts across various datasets in the absence of annotations and fine-tuning. By adding pseudo labeling and self-training, MaskCLIP+ surpasses SOTA transductive zero-shot semantic segmentation methods by large margins.
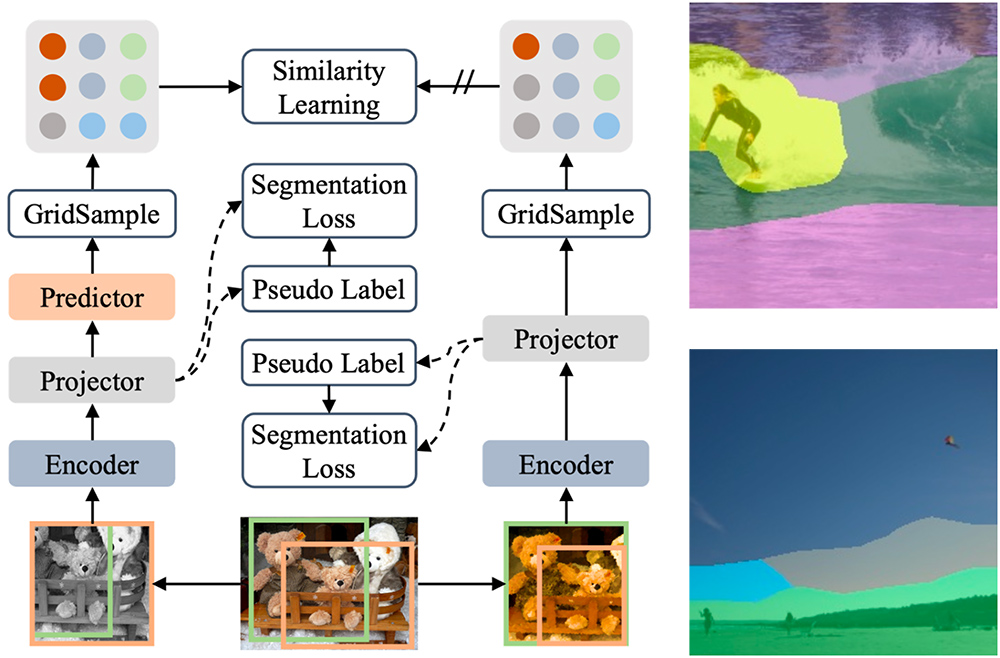
Dense Siamese Network for Dense Unsupervised Learning
W. Zhang, J. Pang, K. Chen, C. C. Loy
European Conference on Computer Vision, 2022 (ECCV)
[PDF]
[arXiv]
[Supplementary Material]
[Project Page]
This paper presents Dense Siamese Network (DenseSiam), a simple unsupervised learning framework for dense prediction tasks. It learns visual representations by maximizing the similarity between two views of one image with two types of consistency, i.e., pixel consistency and region consistency. In contrast to previous methods that require negative pixel pairs, momentum encoders or heuristic masks, DenseSiam benefits from the simple Siamese network and optimizes the consistency of different granularities. It also shows that the simple location correspondence and interacted region embeddings are effective enough to learn the similarity.

Open-Vocabulary DETR with Conditional Matching
Y. Zang, W. Li, K. Zhou, C. Huang, C. C. Loy
European Conference on Computer Vision, 2022 (ECCV, Oral)
[PDF]
[arXiv]
[Supplementary Material]
[Project Page]
We propose a novel open-vocabulary detector based on DETR, which once trained, can detect any object given its class name or an exemplar image. This first end-to-end Transformer-based open-vocabulary detector achieves non-trivial improvements over current state of the arts.

Mind the Gap in Distilling StyleGANs
G. Xu, Y. Hou, Z. Liu, C. C. Loy
European Conference on Computer Vision, 2022 (ECCV)
[PDF]
[arXiv]
[Supplementary Material]
[Project Page]
This paper provides a comprehensive study of distilling from the popular StyleGAN-like architecture. Our key insight is that the main challenge of StyleGAN distillation lies in the output discrepancy issue, where the teacher and student model yield different outputs given the same input latent code. Standard knowledge distillation losses typically fail under this heterogeneous distillation scenario. We conduct thorough analysis about the reasons and effects of this discrepancy issue, and identify that the mapping network plays a vital role in determining semantic information of generated images. Based on this finding, we propose a novel initialization strategy for the student model, which can ensure the output consistency to the maximum extent.

CelebV-HQ: A Large-Scale Video Facial Attributes Dataset
H. Zhu, W. Wu, W. Zhu, L. Jiang, S. Tang, L. Zhang, Z. Liu, C. C. Loy
European Conference on Computer Vision, 2022 (ECCV)
[PDF]
[arXiv]
[Supplementary Material]
[Project Page]
We propose a large-scale, high-quality, and diverse video dataset, named the High-Quality Celebrity Video Dataset (CelebV-HQ), with rich facial attribute annotations. CelebV-HQ contains 35,666 video clips involving 15,653 identities and 83 manually labeled facial attributes covering appearance, action, and emotion. We conduct a comprehensive analysis in terms of ethnicity, age, brightness, motion smoothness, head pose diversity, and data quality to demonstrate the diversity and temporal coherence of CelebV-HQ. Besides, its versatility and potential are validated on unconditional video generation and video facial attribute editing tasks.

StyleGAN-Human: A Data-Centric Odyssey of Human Generation
J. Fu, S. Li, Y. Jiang, K.-Y. Lin, C. Qian, C. C. Loy, W. Wu, Z. Liu
European Conference on Computer Vision, 2022 (ECCV)
[PDF]
[arXiv]
[Supplementary Material]
[Project Page]
[YouTube]
We collect and annotate a large-scale human image dataset with over 230K samples capturing diverse poses and textures. Equipped with this large dataset, we rigorously investigate three essential factors in data engineering for StyleGAN-based human generation, namely data size, data distribution, and data alignment.

HuMMan: Multi-Modal 4D Human Dataset for Versatile Sensing and Modeling
Z. Cai, D. Ren, A. Zeng, Z. Lin, T. Yu, W. Wang, X. Fan, Y. Gao, Y. Yu, L. Pan, F. Hong, M. Zhang, C. C. Loy, L. Yang, Z. Liu
European Conference on Computer Vision, 2022 (ECCV, Oral)
[PDF]
[arXiv]
[Supplementary Material]
[Project Page]
[YouTube]
We contribute HuMMan, a large-scale multi-modal 4D human dataset with 1000 human subjects, 400k sequences and 60M frames. HuMMan has several appealing properties: 1) multi-modal data and annotations including color images, point clouds, keypoints, SMPL parameters, and textured meshes; 2) popular mobile device is included in the sensor suite; 3) a set of 500 actions, designed to cover fundamental movements; 4) multiple tasks such as action recognition, pose estimation, parametric human recovery, and textured mesh reconstruction are supported and evaluated.

Monocular 3D Object Reconstruction with GAN Inversion
J. Zhang, D. Ren, Z. Cai, C. K. Yeo, B. Dai, C. C. Loy
European Conference on Computer Vision, 2022 (ECCV)
[PDF]
[arXiv]
[Supplementary Material]
[Project Page]
Recovering a textured 3D mesh from a monocular image is highly challenging, particularly for in-the-wild objects that lack 3D ground truths. In this work, we present MeshInversion, a novel framework to improve the reconstruction by exploiting the generative prior of a 3D GAN pre-trained for 3D textured mesh synthesis. Reconstruction is achieved by searching for a latent space in the 3D GAN that best resembles the target mesh in accordance with the single view observation. Since the pre-trained GAN encapsulates rich 3D semantics in terms of mesh geometry and texture, searching within the GAN manifold thus naturally regularizes the realness and fidelity of the reconstruction. Importantly, such regularization is directly applied in the 3D space, providing crucial guidance of mesh parts that are unobserved in the 2D space.

LEDNet: Joint Low-light Enhancement and Deblurring in the Dark
S. Zhou, C. Li, C. C. Loy
European Conference on Computer Vision, 2022 (ECCV)
[PDF]
[arXiv]
[Supplementary Material]
[Project Page]
Night photography typically suffers from both low light and blurring issues due to the dim environment and the common use of long exposure. While existing light enhancement and deblurring methods could deal with each problem individually, a cascade of such methods cannot work harmoniously to cope well with joint degradation of visibility and textures. Training an end-to-end network is also infeasible as no paired data is available to characterize the coexistence of low light and blurs. We address the problem by introducing a novel data synthesis pipeline that models realistic low-light blurring degradations. With the pipeline, we present the first large-scale dataset for joint low-light enhancement and deblurring. The dataset, LOL-Blur, contains 12,000 low-blur/normal-sharp pairs with diverse darkness and motion blurs in different scenarios. We further present an effective network, named LEDNet, to perform joint low-light enhancement and deblurring.

BRACE: The Breakdancing Competition Dataset for Dance Motion Synthesis
D. Moltisanti, J. Wu, B. Dai, C. C. Loy
European Conference on Computer Vision, 2022 (ECCV)
[PDF]
[arXiv]
[Supplementary Material]
[Project Page]
We presented BRACE, a new dataset for audio-conditioned dance motion syn- thesis. BRACE was collected to challenge the main assumptions taken by motion synthesis models, i.e. relative simple poses and movement captured with controlled data. We designed an efficient pipeline to annotate poses in videos, striking a good balance between labelling cost and keypoint quality. Our pipeline is flexible and can be adopted for any pose estimation task involving complex movements and dynamic recording settings.

StyleLight: HDR Panorama Generation for Lighting Estimation and Editing
G. Wang, Y. Yang, C. C. Loy, Z. Liu
European Conference on Computer Vision, 2022 (ECCV)
[PDF]
[arXiv]
[Supplementary Material]
[Project Page]
We present a new lighting estimation and editing framework to generate high-dynamic-range (HDR) indoor panorama lighting from a single limited field-of-view (FOV) image captured by low-dynamic-range (LDR) cameras. StyleLight takes FOV-to-panorama and LDR-to-HDR lighting generation into a unified framework and thus greatly improves lighting estimation. StyleLight also enables intuitive lighting editing on indoor HDR panoramas.

Transformer with Implicit Edges for Particle-based Physics Simulation
Y. Shao, C. C. Loy, B. Dai
European Conference on Computer Vision, 2022 (ECCV)
[PDF]
[arXiv]
[Project Page]
Particle-based systems provide a flexible and unified way to simulate physics systems with complex dynamics. Most existing data-driven simulators for particle-based systems adopt graph neural networks (GNNs) as their network backbones, as particles and their interactions can be naturally represented by graph nodes and graph edges. However, while particle-based systems usually contain hundreds even thousands of particles, the explicit modeling of particle interactions as graph edges inevitably leads to a significant computational overhead, due to the increased number of particle interactions. In this paper, we propose a novel Transformer-based method, dubbed as Transformer with Implicit Edges (TIE), to capture the rich semantics of particle interactions in an edge-free manner.
